
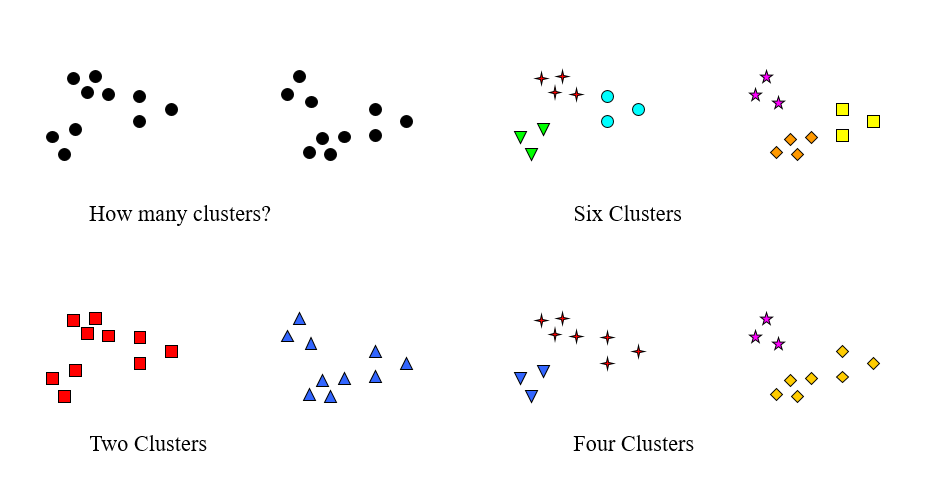
聚类分析将数据划分成有意义或有用的组(簇)。聚类分析仅根据在数据中发现的描述对象及其关系的信息,将数据对象分组。其目标是,组内的对象相互之间是相似的,而不同组中的对象是不同的。
聚类
一个好的聚类方法要能产生高质量的聚类结果——簇,这些簇要具备以下两个特点:
- 高的簇内相似性
- 低的簇间相似性
聚类结果的好坏取决于该聚类方法采用的相似性评估方法以及该方法的具体实现
聚类方法的好坏还取决于该方法是否能发现某些还是所有的隐含模式
聚类可以分为:
- 划分聚类(Partitional Clustering)
- 层次聚类(Hierarchical Clustering)
- 互斥(重叠)聚类(exclusive clustering)
- 非互斥聚类(non-exclusive)
- 模糊聚类(fuzzy clustering)
- 完全聚类(complete clustering)
- 部分聚类(partial clustering)
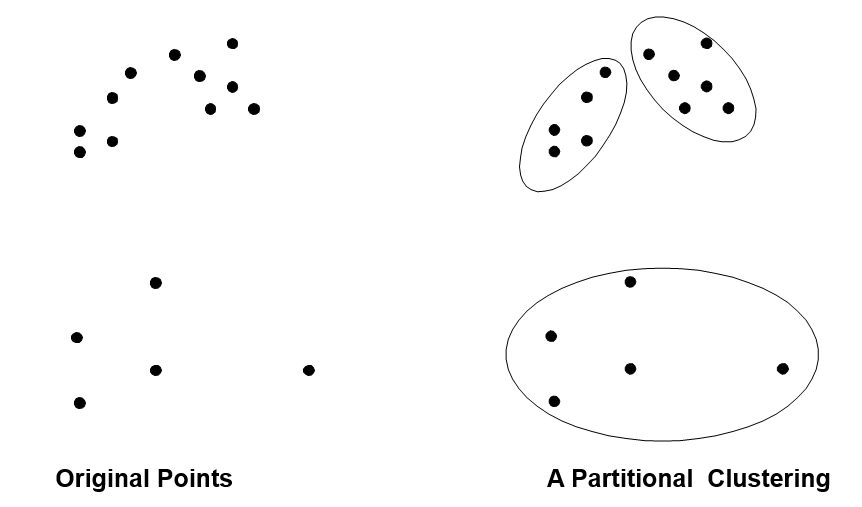
划分聚类
划分聚类简单地将数据对象集划分成不重叠的子集,使得每个数据对象恰在一个子集。
层次聚类
层次聚类是嵌套簇的集族,组织成一棵树。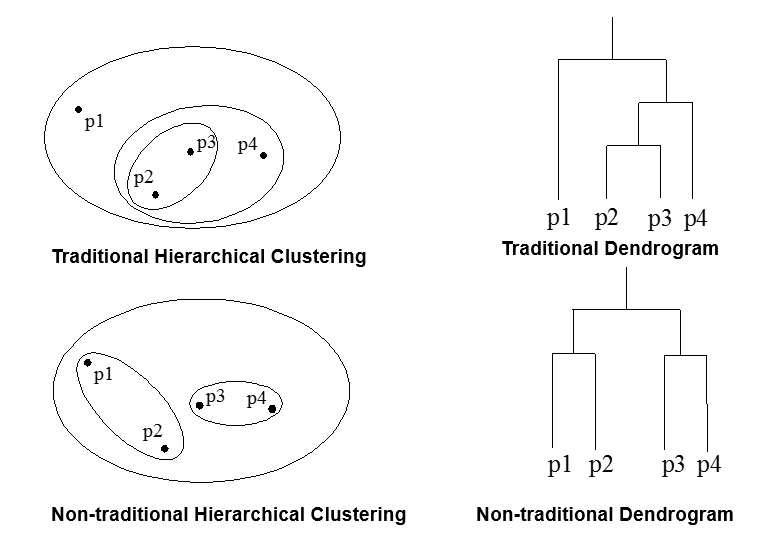
互斥聚类(exclusive)
每个对象都指派到单个簇.
重叠聚类(overlapping)或非互斥聚类(non-exclusive)
聚类用来反映一个对象.同时属于多个组(类)这一事实。
例如:在大学里,一个人可能既是学生,又是雇员
模糊聚类(Fuzzy clustering )
每个对象以一个0(绝对不属于)和1(绝对属于)之间的隶属权值属于每个簇。
换言之,簇被视为模糊集。
部分聚类(Partial)
部分聚类中数据集某些对象可能不属于明确定义的组。如:一些对象可能是离群点、噪声。
完全聚类(complete)
完全聚类将每个对象指派到一个簇。
概念
簇的分类
簇是同一性状物体的集合
按照性状的分类不同可以将簇分为
- 明显分离的
每个点到同簇中任一点的距离比到不同簇中所有点的距离更近。
- 基于原型的
每个对象到定义该簇的原型的距离比到其他簇的原型的距离更近。
对于具有连续属性的数据,簇的原型通常是质心,即簇中所有点的平均值。
当质心没有意义时,原型通常是中心点,即簇中最有代表性的点。
基于中心的( Center-Based)的簇:
每个点到其簇中心的距离比到任何其他簇中心的距离更近。
- 基于图的
如果数据用图表示,其中节点是对象,而边代表对象之间的联系。
簇可以定义为连通分支(connected component):互相连通但不与组外对象连通的对象组。
基于近邻的( Contiguity-Based):其中两个对象是相连的,仅当它们的距离在指定的范围内。这意味着,每个对象到该簇某个对象的距离比到不同簇中任意点的距离更近。
- 基于密度的
簇是对象的稠密区域,被低密度的区域环绕。
概念簇
可以把簇定义为有某种共同性质的对象的集合。
例如:基于中心的聚类。还有一些簇的共同性质需要更复杂的算法才能识别出来。本系列文章将探究各个聚类方式之间的区别