
在数据挖掘中,K-Means算法是一种cluster analysis的算法, 其主要是来计算数据聚集算法,主要通过不断地取离种子点最近均值的算法。
问题
K-Means算法主要解决的问题如下图所示。我们可以看到,在图的左边有一些点,我们用肉眼可以看出来有四个点群,但是我们怎么通过计算机程序找出这几个点群来呢?
于是就出现了我们的K-Means算法。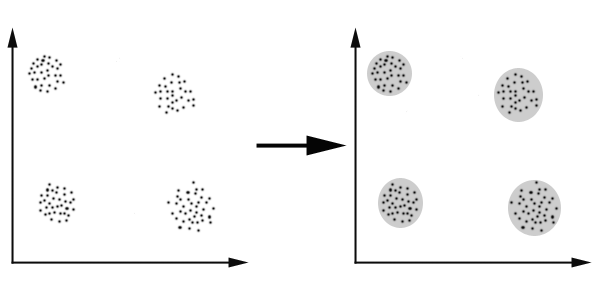
算法概要如下图所示: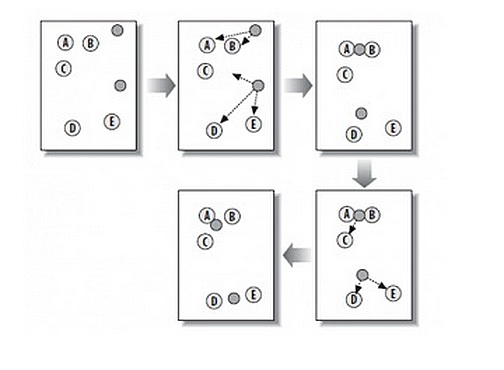
从上图中,我们可以看到,A,B,C,D,E是五个在图中点。而灰色的点是我们的种子点,也就是我们用来找点群的点。有两个种子点,所以K=2。
然后,K-Means的算法如下:
|
|
使用公式可以表示为:
$$\varUpsilon =\sum_{k=1}^K{\sum_{i=1}^L{dist\left( x_i-u_k \right)}}$$
而$dist$距离函数可以分为:
- Minkowski Distance(闵可夫斯基距离)
$$
d_{i,j}=\sqrt[\lambda]{\sum_{k=1}^n{|x_{i,k}-x_{j,k}|}^{\lambda}}
$$
$\lambda$ 可以随意取值,可以是负数,也可以是正数,或是无穷大 - Euclidean Distance(欧拉距离)
$$
d_{i,j}=\sqrt[]{\sum_{k=1}^n{|x_{i,k}-x_{j,k}|}^2}
$$
其形式为 Minkowski Distance 为 $\lambda$=2时候的特殊形式。
- CityBlock Distance (CB距离)
$$
d_{i,j}=\sum_{k=1}^n{|x_{i,k}-x_{j,k}|}
$$
也就是第一个公式 $\lambda$=1的情况。
实验
实验目的
在模拟k-means的实验中我们使用深度学习网络vgg16在一个层的feature maps 来进行模拟实验,用来验证聚类效果,输入图片为一个行人。我们使用vgg16 conv1-2产生的feature maps进行实验。假设我们产生的feature maps 为 $\psi \in R^{m\times n\times k}$ ,其中 $m\times n$ 为feature大小, k为map的个数。首先每个feature进行向量化,从而将其转化为 $\psi \in R^{m* n\times k}$ 。使用k-means对一个层的feature maps进行聚类,并可视化效果。本实验中使用欧式距离。
工具
- 实验使用vlfeat工具包
下载地址: https://github.com/unsky/vlfeat - 在vlfeat\toolbox中使用vl_setup启动工具包
实验过程
假设feature maps已经存在于 res1.mat 中
运行代码
实验结果
- 原始64个feature的可视化:

- k-means (k=10)

k=5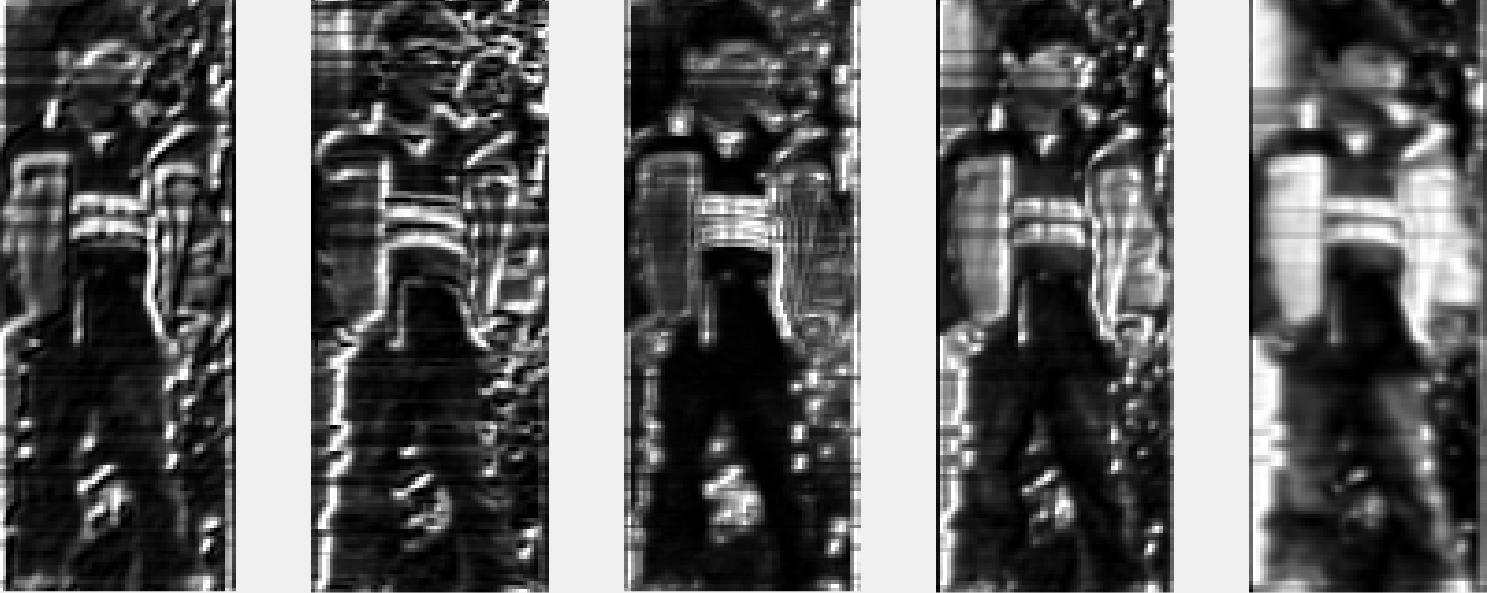
k=1
k-means 优缺点
优点:
- 算法简单
- 适用于球形簇
- 二分k均值等变种算法运行良好,不受初始化问题的影响。
缺点:
- 不能处理非球形簇、不同尺寸和不同密度的簇
- 对离群点、噪声敏感