
CNN-RNN: A Unified Framework for Multi-label ImageClassification
名词区分:
Multi-label Image Classification:给出一张图片,只需指出图片中所有物体即可。
object detection:给出一张图片,要求指出所有物体和其位置。
该篇论文使用了一个同一个CNN-RNN框架来进行图像多标签分类。发表于cvpr 2016.
下载地址:
http://ieeexplore.ieee.org/document/7780620/
#论文的出发点:
一个现实世界的图片不止包含一个物体,应该包含很多物体,传统的多标签图片分类都是为每个类训练独立的分类器,但是这种传统的方式有很多缺点,我们来具体的看下图:
这是三张来自ImageNet 2012分类数据集的图片,但是每张图片只给了一个标签,比如第一张给了飞机这个标签,但是,我们发现,在这张图片中,不止包含了飞机,它还有比如:天空,草地,飞机跑道,甚至是远处若隐若现的楼房。
传统的分类方式,如果想识别这些所有信息,会训练n个分类器进行对上述的每个类别分类,但是这么做的缺点:
1.对小物体的检测性能很低。
2.没有考虑物体之间的出现关系。
对于缺点一,是可想而知的,因为对于小物体拥有很少的像素,能识别的特诊很有局限性,所以很多分类器对它的识别性能很低。
对于缺点二,纵观我们现实世界,物体的出现都是具有逻辑的,比如炸机和啤酒更配,而你看到鲸鱼和狮子同时出现的概率几乎为零。可想而知,飞机在深海中飞行的概率应该只在梦中出现。。。所以,现实世界的物体的出现都是具有逻辑性的。
基于对以上两点的分析,我们能不能寻找一种方法,运用到这种逻辑关系?答案是肯定的,所以提出了CNN-RNN并行框架来进行图片多目标分类。
一看到题目,我们即可从文章的标题中得到作者得思路。在图像识别中,CNN表现出很强得特征提取能力,而LSTM(RNN)对于挖掘信息之间得逻辑关系表现出很好得性能。所以它们之间得连立看起来对上述问题是很好得解决方案。
首先对于基本知识,比如CNN 和LSTM(RNN)得相关知识我们已经有很多得讨论,在这里简单得说一下LSTM:
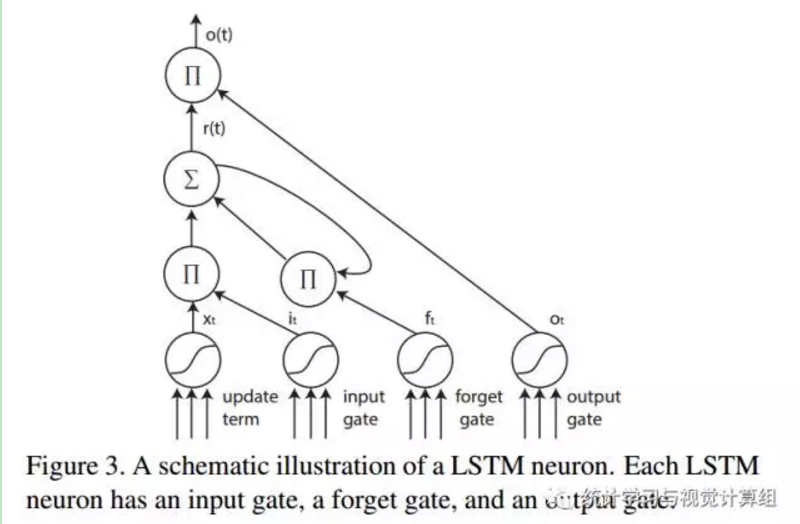
LSTM是一种循环递归网络,它具有长时记忆功能,其神经单元得总成包括一个输入门,一个遗忘门,一个输出门,如上图.
其具体得公式如下:
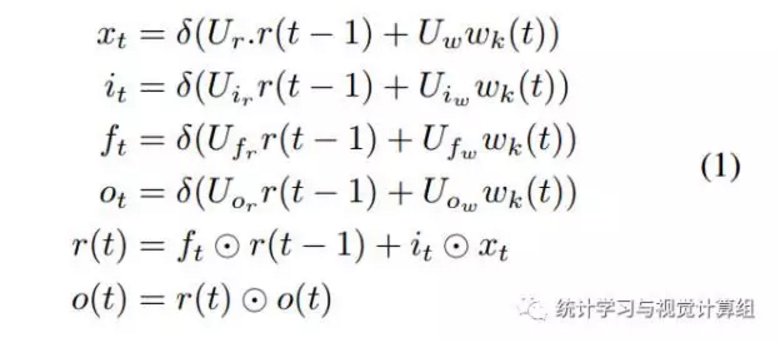 对于时间t,是每次递归得时间点,在这里我们不再将其按时间展开。
对于时间t,是每次递归得时间点,在这里我们不再将其按时间展开。
好了有了以上知识点,直接看作者提出得框架:
然后我们来看作者是怎么做得。
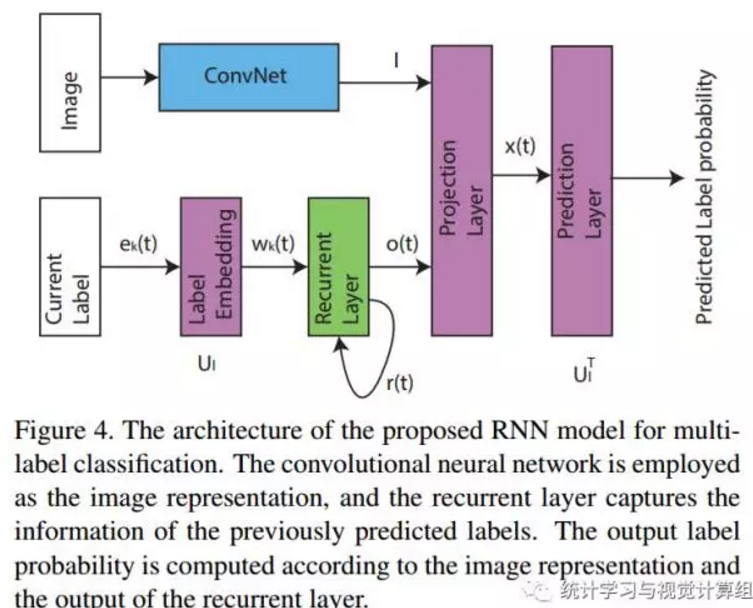
作者得思路就是,靠卷积网络来提取图片得特征,而靠LSTM网络对CNN进行一个目标导向,输入一张图片给CNN,它所看到的视觉是没有目标的,但是如果我们使用LSTM对其进行导向,或许CNN会对LSTM的导向所影响,对于这个问题,作者在后续的试验中会有所探索。
从以上框架看出,CNN部分中规中矩,就是一个特征提取器,实际上确实没有什么改变,作者直接使用了VGG16的卷积层,而且没有进行任何的微调。注意该vgg16的训练来自ImageNet2012的分类数据集。
重点是LSTM部分:
假如一个物体的标签k是:


然后在预测具体的最后一层用个softmax normalization 处理下最后得分就可以了.
综上,我们需要自己训练的东西包括一个LSTM和一个连立的全连接层而已。以上的整体思路就是,
用CNN提出特征,然后得出第一个标签,然后将这个标签输入LSTM,得到下一个标签,再和这个cnn特征联合,输出有没有,然后再输入lstm的下一个预测,一直下去。
对于小物体,我们可以使用LSTM进行猜,如果这个物体在图片中存在,CNN会将焦点聚焦于该物体,如果没有,就没有。。这样对于很小的物体,比如远处若隐若现的楼房,或会会表现很好,后面有实验。
好了,以上就是这个网络的设计,我们来考虑一下细节:
首先我们面临的一个严重的问题就是,我们先把哪个标签输入?
比如飞机的那张图片,我们应该先输入飞机,还是天空还是跑道?
对于这个问题,作者的思路是基于统计学,统计出整个数据集每个物体出现的频率按照该频率进行先后的输入。作者在试验中发现,这种策略会有很好的性能,但是如果我们随机的输入标签顺序,作者发现,这个网路很难收敛。
所以,对于先输入哪个的问题,给出的解决方案就是按频率来。
接下来,我们又遇到一个问题,
对于搜索路径的问题:
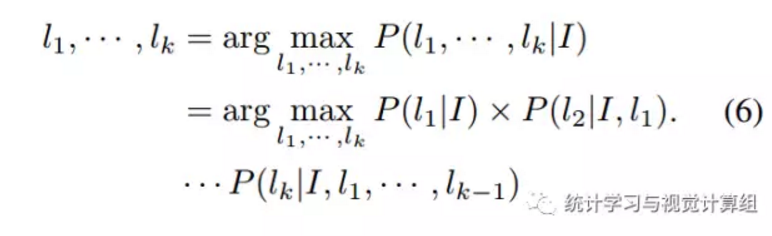
假如我们已经预测了前n个标签,再预测第n+1个的时候,我们应该在剩下的特征集中选择,这种策略是很明显的贪婪算法,贪婪的代价就是性能低,白话一下就是,假如我们第一个预测就错了,我们剩下的所有时间状态的预测是不是就都错了,所以这是贪婪算法的最大缺点。
所以将贪婪搜索换成束搜索:
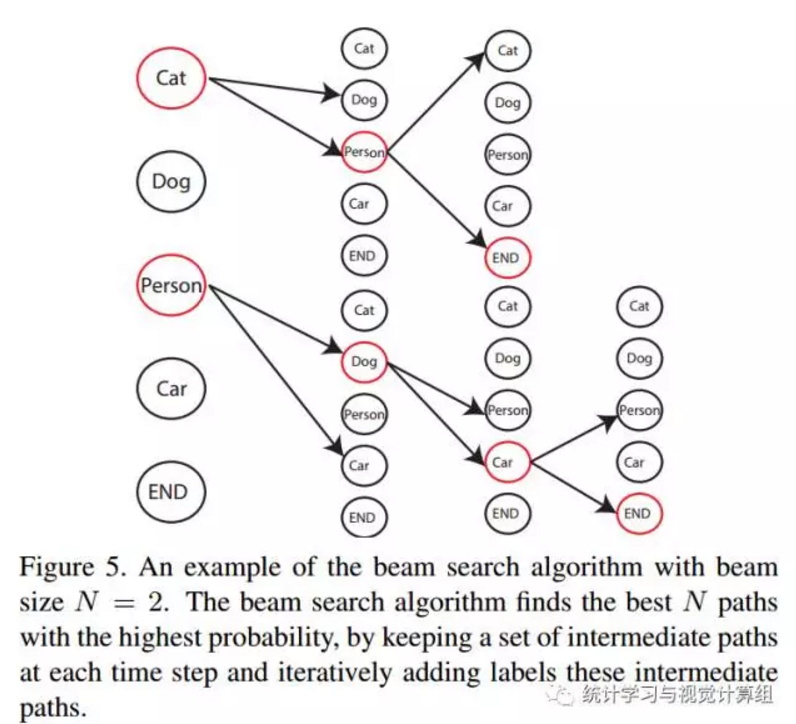
白话一下,就是每一次搜索都会在所有的集合里进行搜索,如上图,这样做,我们还需要考虑一个问题,
我们应该什么时候停止搜索?
作者给出的解决方案是,如果下一个搜索的概率低于当前所有的路径时,我们就停止,如上图的红色,在搜索到第三层时,其概率已经低于当前所有可能搜索路径,我们停止。
实验部分:
然后我们看它的实验,除了各种性能的实验外,最吸引人的实验是作者做了一个可视化实验,可视化lstm对cnn的影响:

如图,我们将上面的图片输入cnn,cnn给的结果是大象(imageNet给的标签也是大象),然后我们将大象输入lstm进行预测,它预测的下一个目标是斑马,(在lstm眼里斑马和大象更配。。)这时递归的斑马对cnn的焦点产生了影响,从第三个图可以看出,cnn开始注重斑马的特征,而开始忽略其它。(我自己感觉这是这篇论文最棒的贡献)
剩下的是性能:
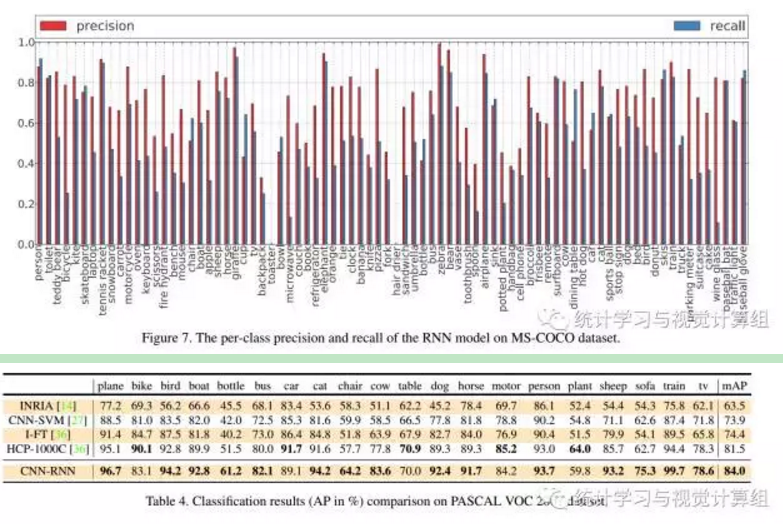
有兴趣的同学可以自己看一下。
几点思考:
1.在cnn卷积的高层,每个核看到的东西更注重各个部位的细节,我们可以使用策略将其引导到我们更加希望让cnn看到的焦点上。
2.对于小物体,在有限的像素点上,我们可以先猜,然后再然cnn判断是不是,这点是很符合人类的思考模式的。
比如,我们看远方一个不知道是啥的一个黑色物体,我们大脑的反应是,先猜,思考逻辑:
lstm:是黑色汽车?
cnn:应该不是,它在动。
lstm:那是乌鸦?
cnn:应该不是,它没有尖尖的嘴。
lstm:那是黑色塑料带?
cnn:你别说,还真像。。。
lstm: ………..