
在神经元的数学模型中,轴突所携带的信号(例如: $x_0$ )通过突触进行传递,由于突触的强弱不一,假设我们以 $w_0$ 表示,那么我们传到下一个神经元的树突处的信号就变成了 $w_0x_0$ 。其中突触强弱(参数w)是可学的,它控制了一个神经元对另一个神经元影响的大小和方向(正负)。然后树突接收到信号后传递到神经元内部cell body,与其他树突传递过来的信号一起进行加和,如果这个和的值大于某一个固定的阈值的话,神经元就会被激活,然后传递冲激信号给树突。在数学模型中我们假设传递冲激信号的时间长短并不重要,只有神经元被激活的频率用于传递信息. 我们将是否激活神经元的函数称为激活函数(activation function $f$ ), 它代表了轴突接收到冲激信号的频率。以前我们比较常用的一个激活信号是sigmoid function $σ$ ,因为它接收一个实值的信号(即上面所说的加和的值)然后将它压缩到 0-1 的范围内。我们在后面会介绍更多的激活函数。
传统Sigmoid系激活函数
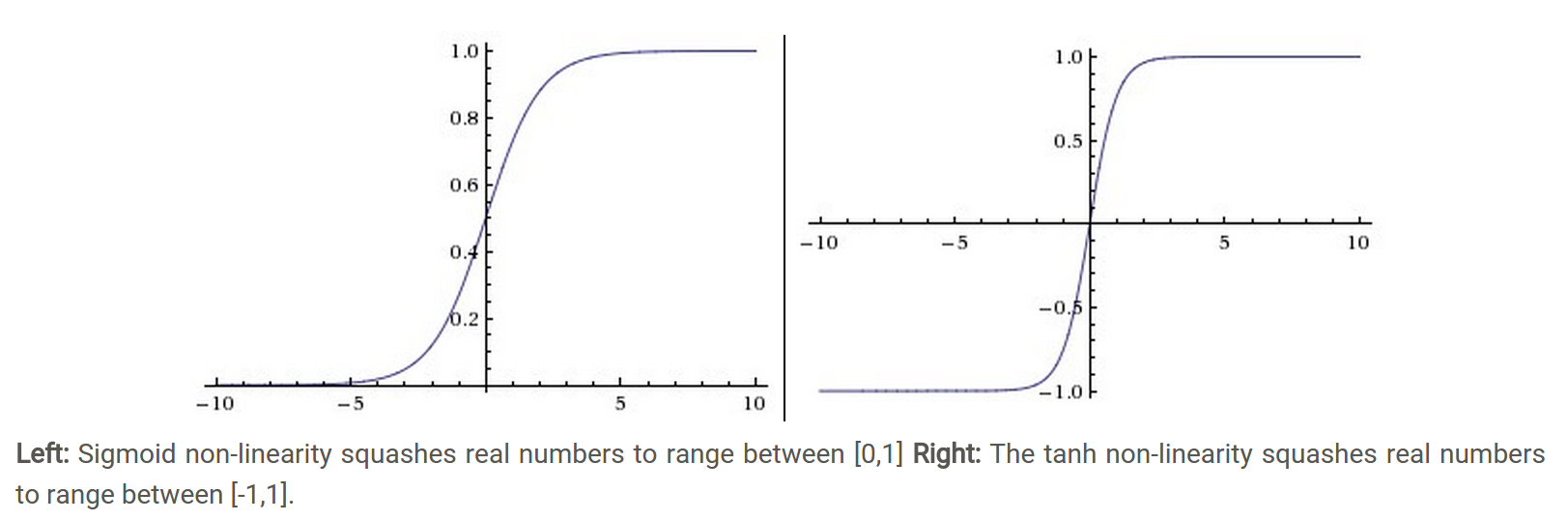
传统神经网络中最常用的两个激活函数,Sigmoid系(Logistic-Sigmoid、Tanh-Sigmoid)被视为神经网络的核心所在。从数学上来看,非线性的Sigmoid函数对中央区的信号增益较大,对两侧区的信号增益小,在信号的特征空间映射上,有很好的效果。从神经科学上来看,中央区酷似神经元的兴奋态,两侧区酷似神经元的抑制态,因而在神经网络学习方面,可以将重点特征推向中央区,将非重点特征推向两侧区。
sigmoid激活函数
sigmoid将一个实数输入映射到[0,1]范围内,如下图(左)所示。使用sigmoid作为激活函数存在以下几个问题:
- 梯度饱和。当函数激活值接近于0或者1时,函数的梯度接近于0。在反向传播计算梯度过程中:
$$\delta^{\left(l\right)}=\left( W^{\left(l\right)} \right) ^T\delta ^{\left(l+1\right)}\cdot f’\left( z^{\left(L\right)}\right) $$
,每层残差接近于0,计算出的梯度也不可避免地接近于0。这样在参数微调过程中,会引起参数弥散问题,传到前几层的梯度已经非常靠近0了,参数几乎不会再更新。 - 函数输出不是以0为中心的。我们更偏向于当激活函数的输入是0时,输出也是0的函数.
tanh激活函数
tanh函数将一个实数输入映射到[-1,1]范围内,如上图(右)所示。当输入为0时,tanh函数输出为0,符合我们对激活函数的要求。然而,tanh函数也存在梯度饱和问题,导致训练效率低下。
Softplus&ReLu
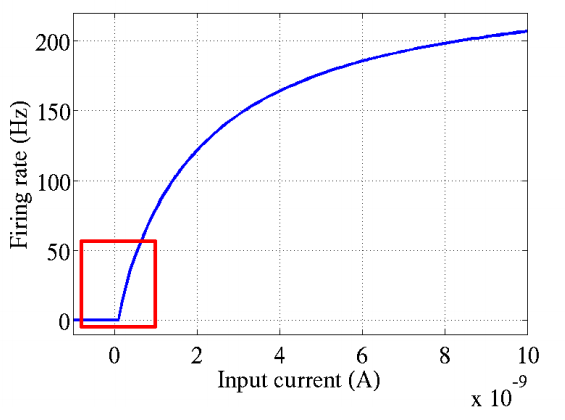
2001年,神经科学家Dayan、Abott从生物学角度,模拟出了脑神经元接受信号更精确的激活模型,该模型如左图所示:这个模型对比Sigmoid系主要变化有三点:单侧抑制 相对宽阔的兴奋边界 稀疏激活性(重点,可以看到红框里前端状态完全没有激活)
同年,Charles Dugas等人在做正数回归预测论文中偶然使用了Softplus函数,Softplus函数是Logistic-Sigmoid函数原函数。
Softplus
激活函数公式:
$$softplus\left( x \right) =\log \left( 1+e^x \right)
$$
按照论文的说法,一开始想要使用一个指数函数(天然正数)作为激活函数来回归,但是到后期梯度实在太大,难以训练,于是加了一个log来减缓上升趋势。
加了1是为了保证非负性。同年,Charles Dugas等人在NIPS会议论文中又调侃了一句,Softplus可以看作是强制非负校正函数 $max(0,x)$ 平滑版本。
偶然的是,同是2001年,ML领域的Softplus/Rectifier激活函数与神经科学领域的提出脑神经元激活频率函数有神似的地方,这促成了新的激活函数的研究。
ReLU
Relu激活函数(The Rectified Linear Unit)表达式为:
$$f(x)=max(0,x)$$
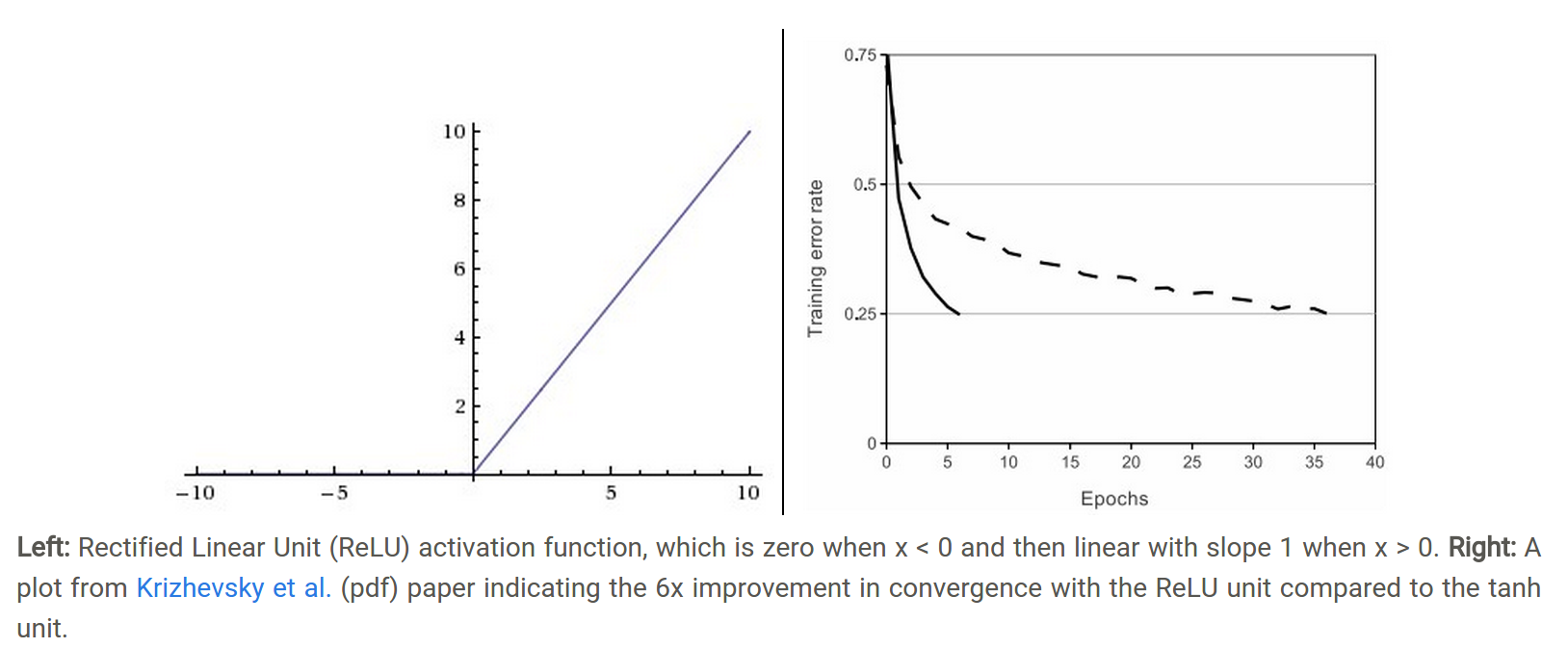
相比sigmoid和tanh函数,Relu激活函数的优点在于:
梯度不饱和。梯度计算公式为:1{x>0}。因此在反向传播过程中,减轻了梯度弥散的问题,神经网络前几层的参数也可以很快的更新。计算速度快。正向传播过程中,sigmoid和tanh函数计算激活值时需要计算指数,而Relu函数仅需要设置阈值。如果x<0,f(x)=0,如果x>0,f(x)=x。加快了正向传播的计算速度。
因此,Relu激活函数可以极大地加快收敛速度,相比tanh函数,收敛速度可以加快6倍(如上图(右)所示)。
激活函数的发展
PReLU
dsd
PReLU 是ReLU 和 LReLU的改进版本,具有非饱和性:
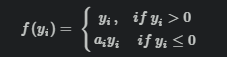
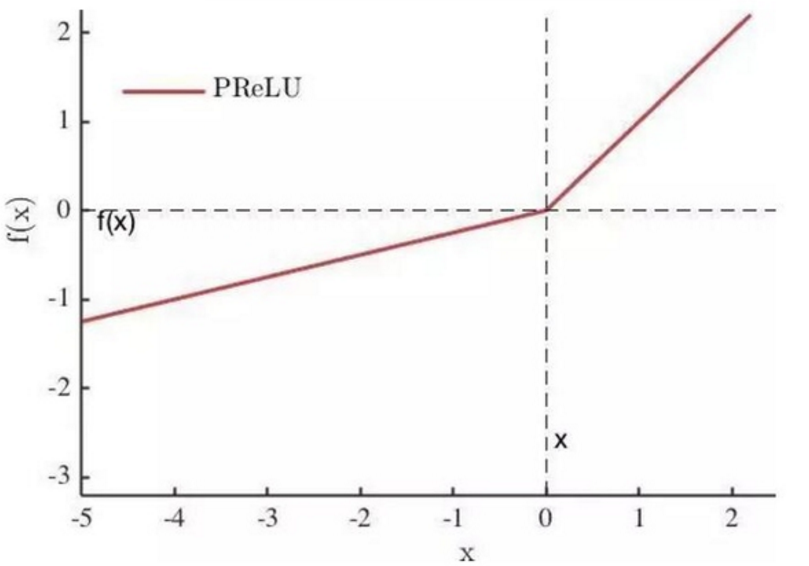
与LReLU相比,PReLU中的负半轴斜率a可学习而非固定。原文献建议初始化a为0.25,不采用正则。个人认为,是否采用正则应当视具体的数据库和网络,通常情况下使用正则能够带来性能提升。
虽然PReLU 引入了额外的参数,但基本不需要担心过拟合。例如,在上述cifar10+NIN实验中, PReLU比ReLU和ELU多引入了参数,但也展现了更优秀的性能。所以实验中若发现网络性能不好,建议从其他角度寻找原因。
与ReLU相比,PReLU收敛速度更快。因为PReLU的输出更接近0均值,使得SGD更接近natural gradient。证明过程参见原文[10]。
此外,作者在ResNet 中采用ReLU,而没有采用新的PReLU。这里给出个人浅见,不一定正确,仅供参考。首先,在上述LReLU实验中,负半轴斜率对性能的影响表现出一致性。对PReLU采用正则将激活值推向0也能够带来性能提升。这或许表明,小尺度或稀疏激活值对深度网络的影响更大。其次,ResNet中包含单位变换和残差两个分支。残差分支用于学习对单位变换的扰动。如果单位变换是最优解,那么残差分支的扰动应该越小越好。这种假设下,小尺度或稀疏激活值对深度网络的影响更大。此时,ReLU或许是比PReLU更好的选择.
RReLU
数学形式与PReLU类似,但RReLU[9]是一种非确定性激活函数,其参数是随机的。这种随机性类似于一种噪声,能够在一定程度上起到正则效果。作者在cifar10/100上观察到了性能提升。
Maxout
Maxout[13]是ReLU的推广,其发生饱和是一个零测集事件(measure zero event)。正式定义为:
$$\max \left( w_{1}^{T}x+b_1,…,w_{n}^{T}x+b_n \right) $$
Maxout网络能够近似任意连续函数,且当w2,b2,…,wn,bn为0时,退化为ReLU。 其实,Maxout的思想在视觉领域存在已久。例如,在HOG特征里有这么一个过程:计算三个通道的梯度强度,然后在每一个像素位置上,仅取三个通道中梯度强度最大的数值,最终形成一个通道。这其实就是Maxout的一种特例。
Maxout能够缓解梯度消失,同时又规避了ReLU神经元死亡的缺点,但增加了参数和计算量。
ELU
ELU 融合了sigmoid和ReLU,具有左侧软饱性。其正式定义为:
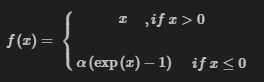
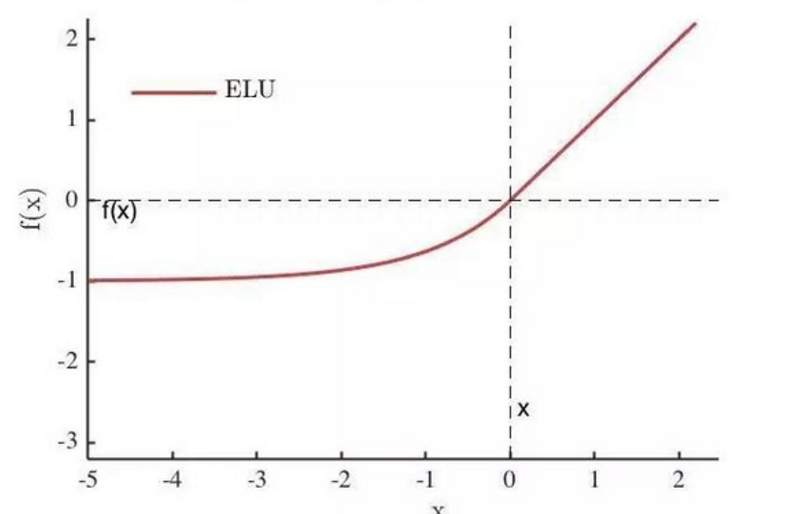
右侧线性部分使得ELU能够缓解梯度消失,而左侧软饱能够让ELU对输入变化或噪声更鲁棒。ELU的输出均值接近于零,所以收敛速度更快。经本文作者实验,ELU的收敛性质的确优于ReLU和PReLU。在cifar10上,ELU 网络的loss 降低速度更快;在 ImageNet上,不加 Batch Normalization 30 层以上的 ReLU 网络会无法收敛,PReLU网络在MSRA的Fan-in (caffe )初始化下会发散,而 ELU 网络在Fan-in/Fan-out下都能收敛 。
论文的另一个重要贡献是分析了Bias shift 现象与激活值的关系,证明了降低Bias shift 等价于把激活值的均值推向0。
MPELU
将分段线性与ELU统一到了一种形式下。在NIN+CIFAR10,本文作者发现ELU与LReLU性能一致,而与PReLU差距较大。经过分析,ELU泰勒展开的一次项就是LReLU。当在ELU前加入BN让输入集中在0均值附近, 则ELU与LReLU之差——泰勒展开高次项会变小,粗略估计,约55.57%的激活值误差小于0.01。因此,受PReLU启发,令α可学习能够提高性能。此外,引入参数β能够进一步控制ELU的函数形状。正式定义为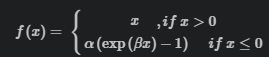
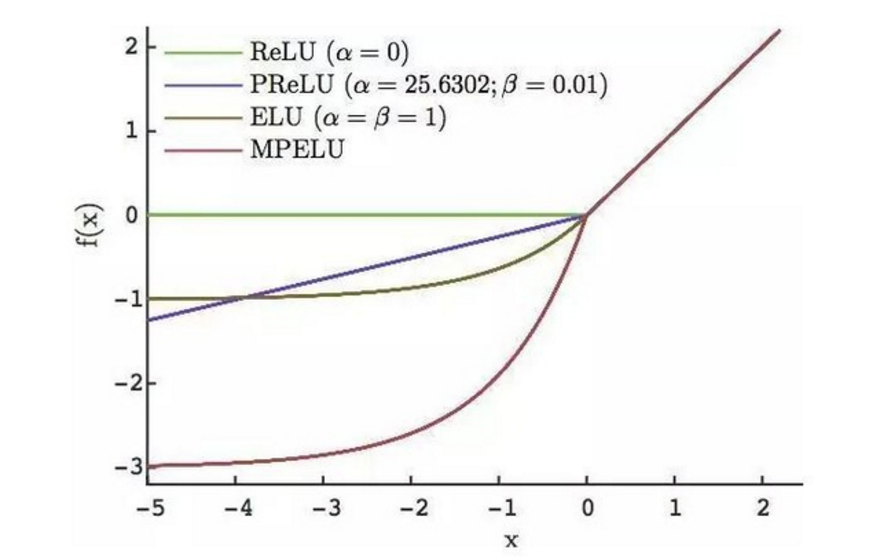
α 和 β可以使用正则。α, β 固定为1时,MPELU 退化为 ELU; β 固定为很小的值时,MPELU 近似为 PReLU;当α=0,MPELU 等价于 ReLU。
MPELU 的优势在于同时具备 ReLU、PReLU和 ELU的优点。首先,MPELU具备ELU的收敛性质,能够在无 Batch Normalization 的情况下让几十层网络收敛。其次,作为一般化形式, MPELU较三者的推广能力更强。简言之,MPELU = max(ReLU, PReLU, ELU)。