
Deep Learning Strong Parts for Pedestrian Detection 是发表在iccv2015的文章。
本论文的核心思想是遮挡的处理问题。
出发点
传统的行人检测对遮挡行人的处理都是用单分类器进行处理,这篇论文,将不再适用单分类器,而是用多分类器处理遮挡问题。同时这种方法是基于分块的。
论文贡献
- 构建了一个部件池包含很多行人的分块,这些分块是自动选择的而且适用于不同的数据集。
- 基于各种CovNets,对各种分块分别训练一个网络,而不是单个分类器。
提出了一种解决偏移的方法。
方法
部件池的构建

讲一个行人切分成2mm个cell,在具体的试验中m=3.
就是18个cell,
然后适用一个hw的滑动窗口在cell上滑动,步长是1,其中h和w满足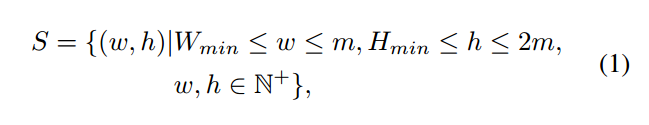
就是限制他们的大小,不能太小,太小了没意义。最后在实验的时候最小都取了2.这样通过滑动,总共可以选择出45个这种部件。构造除了我们的部件池。用如下的公式表示
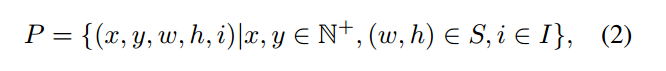
x,y是左上的坐标,w,h是高,i是id,总共45个 这种表示方法的意思就是如果是整个图像就是(1,1,m,2m,id)
训练
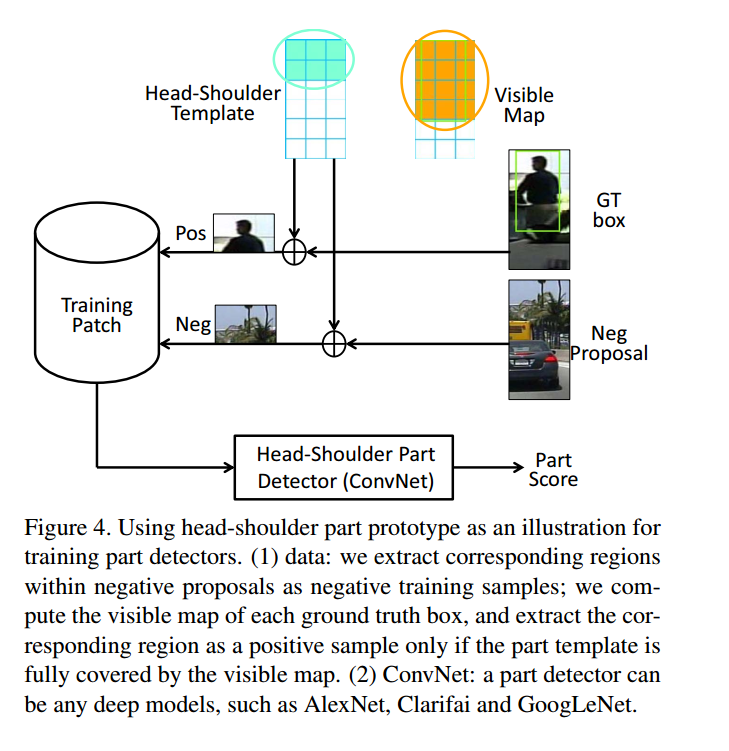
对于负样本直接滑动出45个部件,
对于正样本,需要选择,如果可见部分超过0.4就选择其是人的部件为正样本。如果这个人没又遮挡,直接滑动出45个部分。这样正负样本总共包含45部分,拿着这45种部件,训练45个探测器。。。(内心os:这居然是优点·····)
对于探测器直接用了pre-train的模型,然后进行fine-turning,
fine-turning阶段吐槽一下作者的原话:
|
|
相当于重新训练一次了。。。
处理偏移
为了接收任意尺寸的图片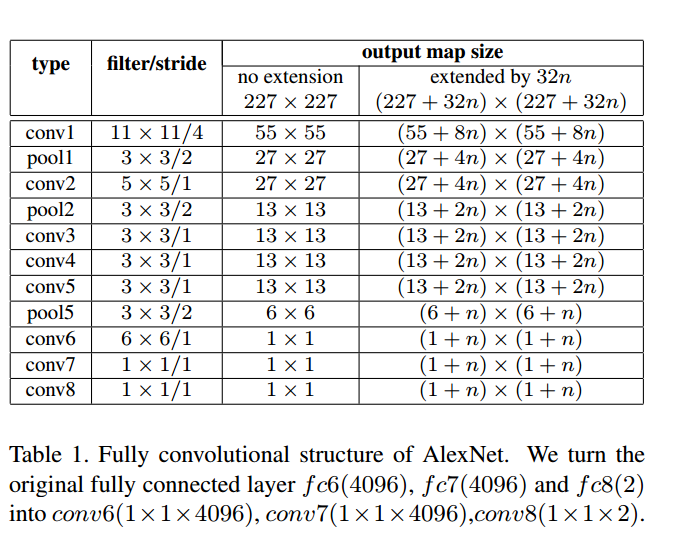
他们把最后的全连接层换成了卷积层,这样就可以接收任意的尺寸了。
以下拿AlexNet为例子
因为AlexNet的感受野的步长是32
所以对原始的候选框进行抖动扩充: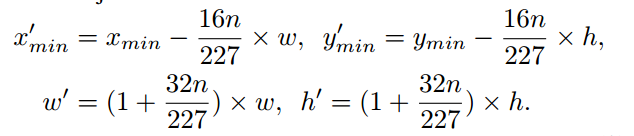
其中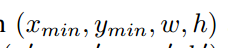 是原始图像,这个公式的意思就是按照神经网络的步长进行比例的扩充。这样最终的卷积层产生的就是(1+n)(1+n)4096的score map。
是原始图像,这个公式的意思就是按照神经网络的步长进行比例的扩充。这样最终的卷积层产生的就是(1+n)(1+n)4096的score map。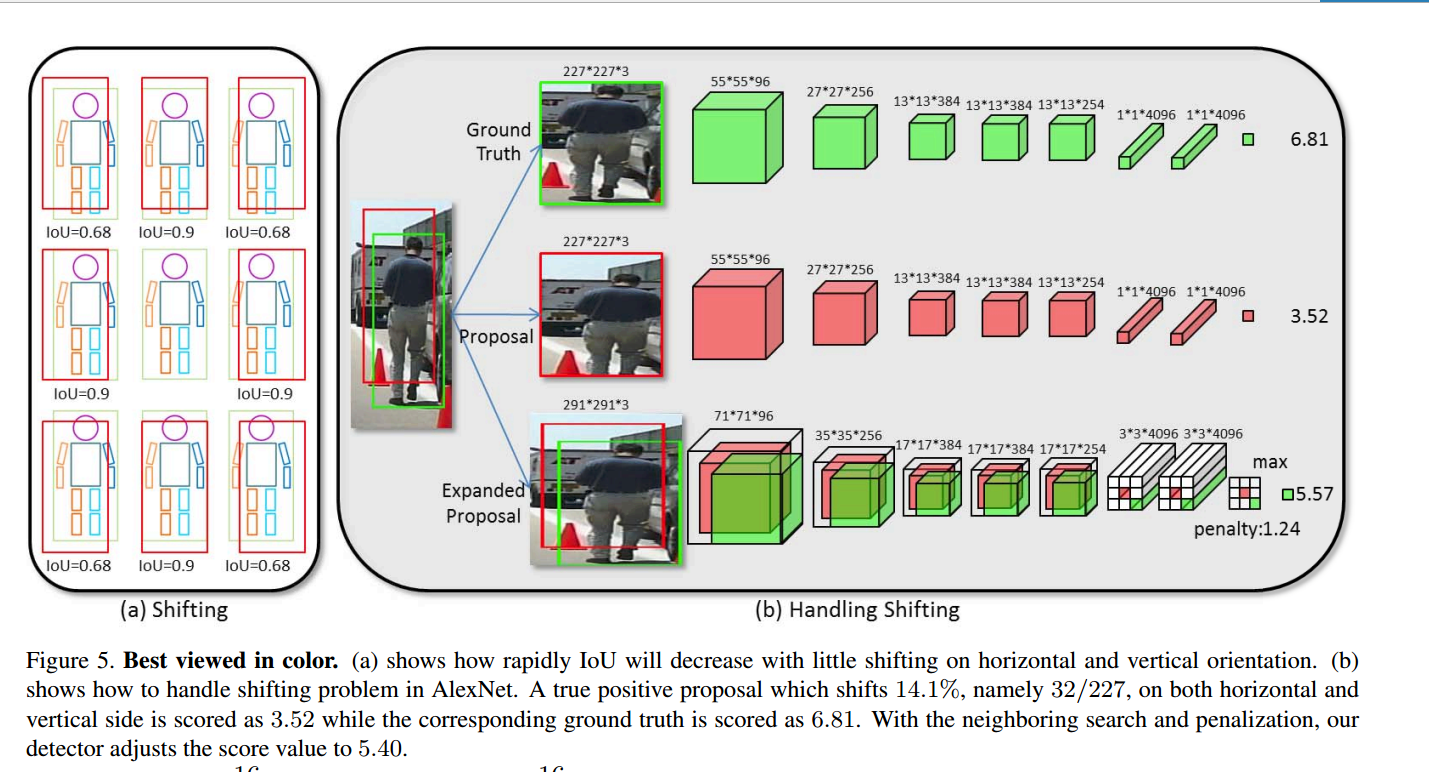
作者先解释了一下偏移问题的重要性,然后拿了一个n=2的例子进行的讲解。
在这里,因为最终生成的是(1+n)(1+n)4096的score map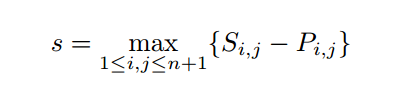
所以直接对其加入惩罚之后进行max(相当于max pooling)
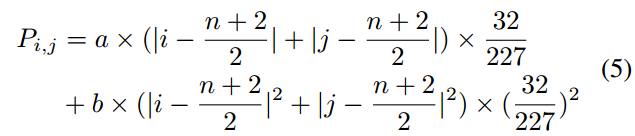
其实这个惩罚就是原位置的加权,
在实验中他们探究了a和b的值, 上图的例子中a=2 b=10.
部件补充
和R-CNN不同,它去掉了svm的分类,直接拿45个部件的114096的进行svm分类。。来判断最终的分类结果。。。
实验
在AlexNet测试了三种部件:

加入偏移处理之后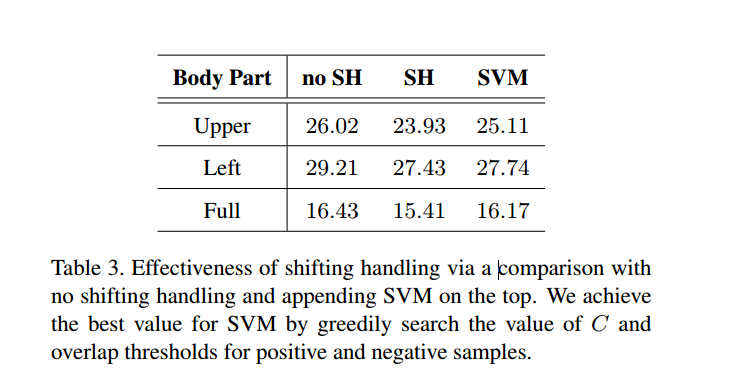
三种模型上的三种部件对比:
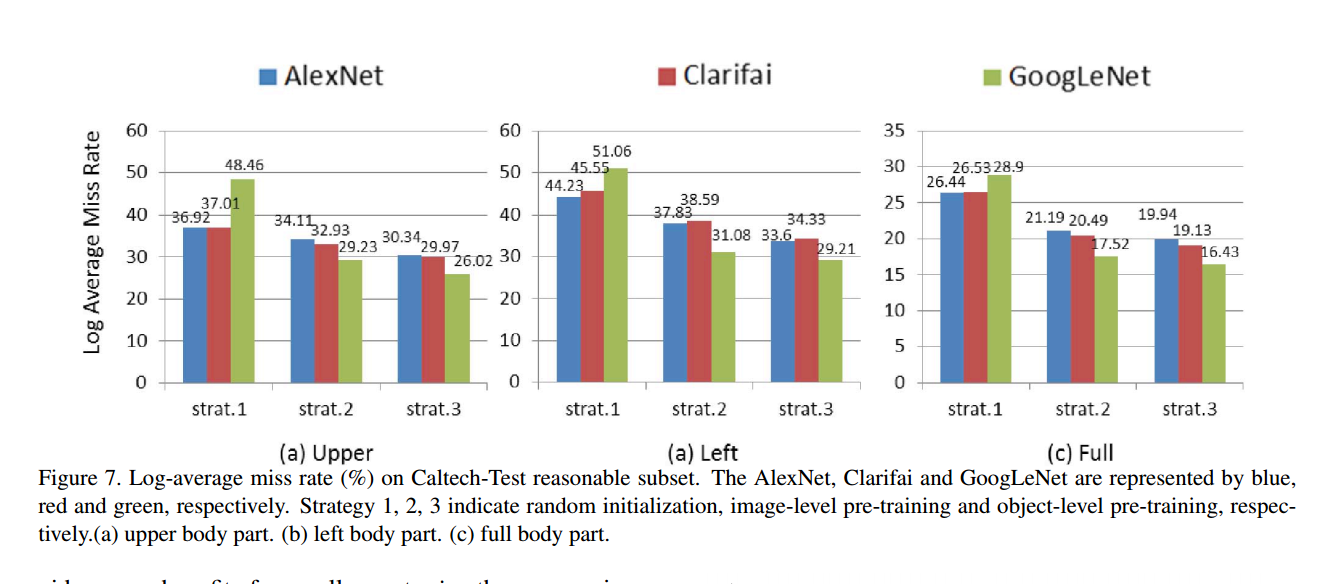
整体在caltech-test
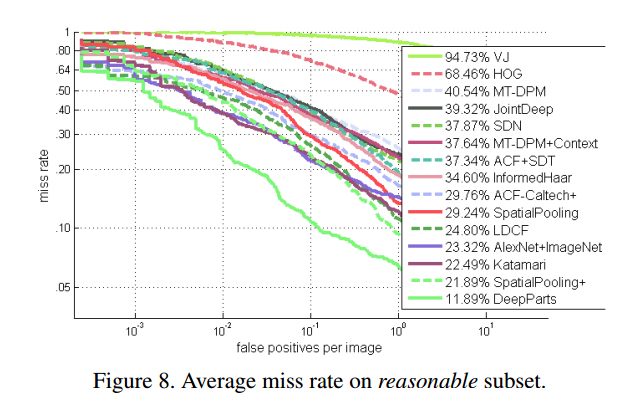
上的结果。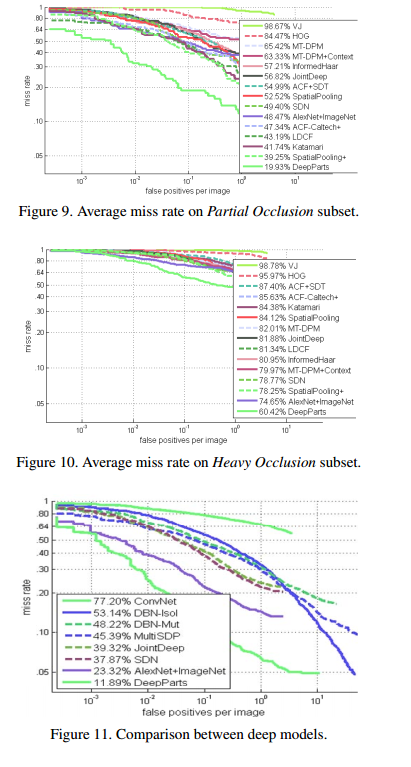
其他数据集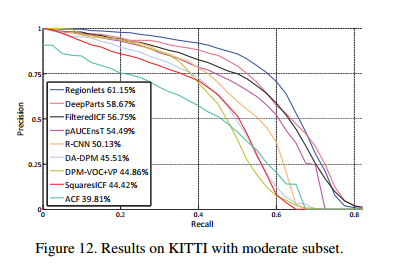
前六个分数最高的部件和随机选的六个部件。