
神经网络算法领域最初是被对生物神经系统建模这一目标启发,但随后与其分道扬镳,成为一个工程问题,并在机器学习领域取得良好效果。然而,讨论将还是从对生物系统的一个高层次的简略描述开始,因为神经网络毕竟是从这里得到了启发.
神经元建模
大脑的基本计算单位是神经元(neuron)。人类的神经系统中大约有860亿个神经元,它们被大约10^14-10^15个突触(synapses)连接起来。下面图表的左边展示了一个生物学的神经元,右边展示了一个常用的数学模型。每个神经元都从它的树突获得输入信号,然后沿着它唯一的轴突(axon)产生输出信号。轴突在末端会逐渐分枝,通过突触和其他神经元的树突相连。
在神经元的计算模型中,沿着轴突传播的信号(比如 $x_0$ )将基于突触的突触强(比如 $w_0$ ),与其他神经元的树突进行乘法交互(比如$w_0x_0$)。其观点是,突触的强度(也就是权重),是可学习的且可以控制一个神经元对于另一个神经元的影响强度(还可以控制影响方向:使其兴奋(正权重)或使其抑制(负权重))。在基本模型中,树突将信号传递到细胞体,信号在细胞体中相加。如果最终之和高于某个阈值,那么神经元将会激活,向其轴突输出一个峰值信号。在计算模型中,我们假设峰值信号的准确时间点不重要,是激活信号的频率在交流信息。基于这个速率编码的观点,将神经元的激活率建模为激活函数(activation function)f,它表达了轴突上激活信号的频率。由于历史原因,激活函数常常选择使用sigmoid函数 $\sigma$,该函数输入实数值(求和后的信号强度),然后将输入值压缩到0-1之间。在本节后面部分会看到这些激活函数的各种细节。
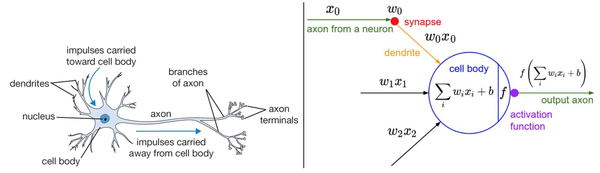
左边是生物神经元,右边是数学模型。
前向传播
卷积
自然图像有其固有特性,也就是说,图像的一部分的统计特性与其他部分是一样的。这也意味着我们在这一部分学习的特征也能用在另一部分上,所以对于这个图像上的所有位置,我们都能使用同样的学习特征。
更恰当的解释是,当从一个大尺寸图像中随机选取一小块,比如说 8x8 作为样本,并且从这个小块样本中学习到了一些特征,这时我们可以把从这个 8x8 样本中学习到的特征作为探测器,应用到这个图像的任意地方中去。特别是,我们可以用从 8x8 样本中所学习到的特征跟原本的大尺寸图像作卷积,从而对这个大尺寸图像上的任一位置获得一个不同特征的激活值。
下面给出一个具体的例子:假设你已经从一个 96x96 的图像中学习到了它的一个 8x8 的样本所具有的特征,假设这是由有 100 个隐含单元的自编码完成的。为了得到卷积特征,需要对 96x96 的图像的每个 8x8 的小块图像区域都进行卷积运算。也就是说,抽取8x8 的小块区域,并且从起始坐标开始依次标记为(1,1),(1,2),…,一直到(89,89),然后对抽取的区域逐个运行训练过的稀疏自编码来得到特征的激活值。在这个例子里,显然可以得到 100 个集合,每个集合含有 89x89 个卷积特征。
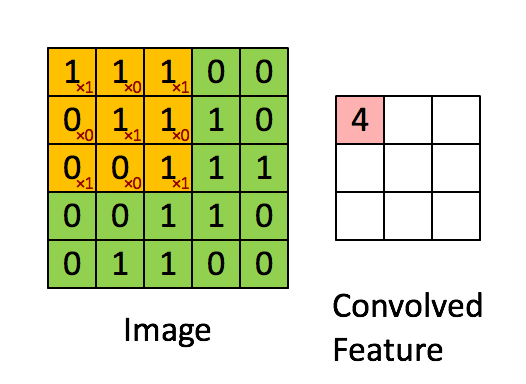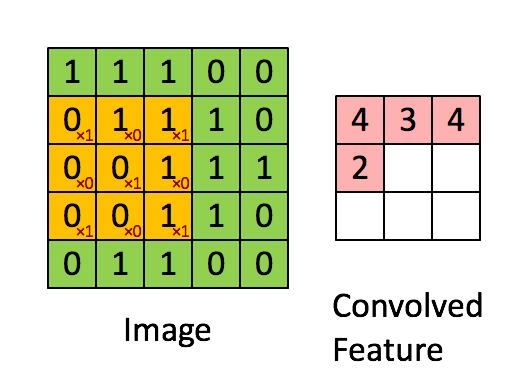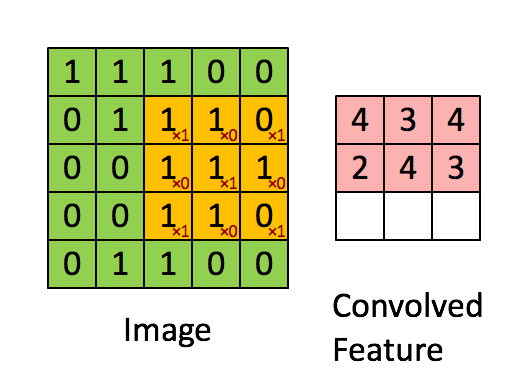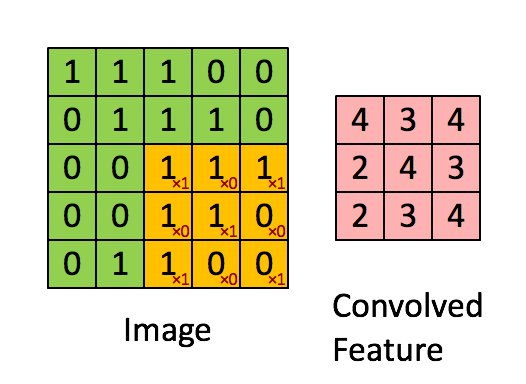
假设给定了 $r \times c$ 的大尺寸图像,将其定义为 xlarge。首先通过从大尺寸图像中抽取的 $a \times b$ 的小尺寸图像样本 $x_{small}$ 训练稀疏自编码,计算 $f = σ(W(1)x_{small} + b(1))$ (σ 是一个 sigmoid 型函数)得到了 k 个特征, 其中 W(1) 和 b(1) 是可视层单元和隐含单元之间的权重和偏差值。对于每一个 $a \times b$ 大小的小图像 $x_s$,计算出对应的值 $f_s = σ(W(1)x_s + b(1))$ ,对这些 fconvolved 值做卷积,就可以得到 $k \times (r - a + 1) \times (c - b + 1)$ 个卷积后的特征的矩阵。
窄卷积 vs 宽卷积
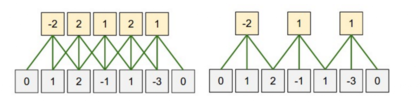
在上文中解释卷积运算的时候,忽略了如何使用滤波器的一个小细节。在矩阵的中部使用3x3的滤波器没有问题,在矩阵的边缘该怎么办呢?左上角的元素没有顶部和左侧相邻的元素,该如何滤波呢?解决的办法是采用补零法(zero-padding)。所有落在矩阵范围之外的元素值都默认为0。这样就可以对输入矩阵的每一个元素做滤波了,输出一个同样大小或是更大的矩阵。补零法又被称为是宽卷积,不使用补零的方法则被称为窄卷积。在具体的试验中就是pad字段设置 0 or other
1D的例子如图所示:
 窄卷积 vs 宽卷积。滤波器长度为5,输入长度为7。
窄卷积 vs 宽卷积。滤波器长度为5,输入长度为7。
步长
卷积运算的另一个超参数是步长,即每一次滤波器平移的距离。上面所有例子中的步长都是1,相邻两个滤波器有重叠。步长越大,则用到的滤波器越少,输出的值也越少.
在实验中使用strike进行控制
池化 pooling
卷积神经网络的一个重要概念就是池化层,一般是在卷积层之后。池化层对输入做降采样。常用的池化做法是对每个滤波器的输出求最大值。我们并不需要对整个矩阵都做池化,可以只对某个窗口区间做池化。例如,下图所示的是2x2窗口的最大值池化(在NLP里,我们通常对整个输出做池化,每个滤波器只有一个输出值):
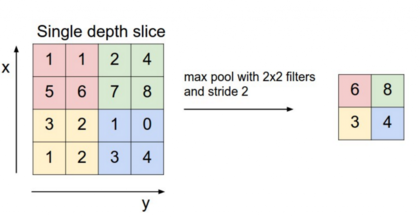
池化的特点之一就是它输出一个固定大小的矩阵,这对分类问题很有必要。例如,如果你用了1000个滤波器,并对每个输出使用最大池化,那么无论滤波器的尺寸是多大,也无论输入数据的维度如何变化,你都将得到一个1000维的输出。这让你可以应用不同长度的句子和不同大小的滤波器,但总是得到一个相同维度的输出结果,传入下一层的分类器。
池化还能降低输出结果的维度,(理想情况下)却能保留显著的特征。你可以认为每个滤波器都是检测一种特定的特征,例如,检测句子是否包含诸如“not amazing”等否定意思。如果这个短语在句子中的某个位置出现,那么对应位置的滤波器的输出值将会非常大,而在其它位置的输出值非常小。通过采用取最大值的方式,能将某个特征是否出现在句子中的信息保留下来,但是无法确定它究竟在句子的哪个位置出现。这个信息出现的位置真的很重要吗?确实是的,它有点类似于一组n-grams模型的行为。尽管丢失了关于位置的全局信息(在句子中的大致位置),但是滤波器捕捉到的局部信息却被保留下来了,比如“not amazing”和“amazing not”的意思就大相径庭。
在图像识别领域,池化还能提供平移和旋转不变性。若对某个区域做了池化,即使图像平移/旋转几个像素,得到的输出值也基本一样,因为每次最大值运算得到的结果总是一样的
前向
现在设节点 $i$ 和节点 $j$ 之间的权值为 $w_{i,j}$ ,节点 $j$ 的阀值为 $b_j$ ,每个节点的输出值为 $x_j$ ,而每个节点的输出值是根据上层所有节点的输出值、当前节点与上一层所有节点的权值和当前节点的阀值还有激活函数来实现的。具体计算方法如下
$$S_j=\sum_{i=0}^{m-1}{w_{i,j}x_i+b_j}$$
$$x_j=f\left( S_j \right) $$
其中 $f$ 为激活函数,一般选取S型函数或者线性函数。正向传递的过程比较简单,按照上述公式计算即可。在BP神经网络中,输入层节点没有阀值。
卷积的前向
如下图,卷积层的输入来源于输入层或者pooling层。每一层的多个卷积核大小相同,在这个网络中,使用的卷积核均为 $5\times 5$ 。
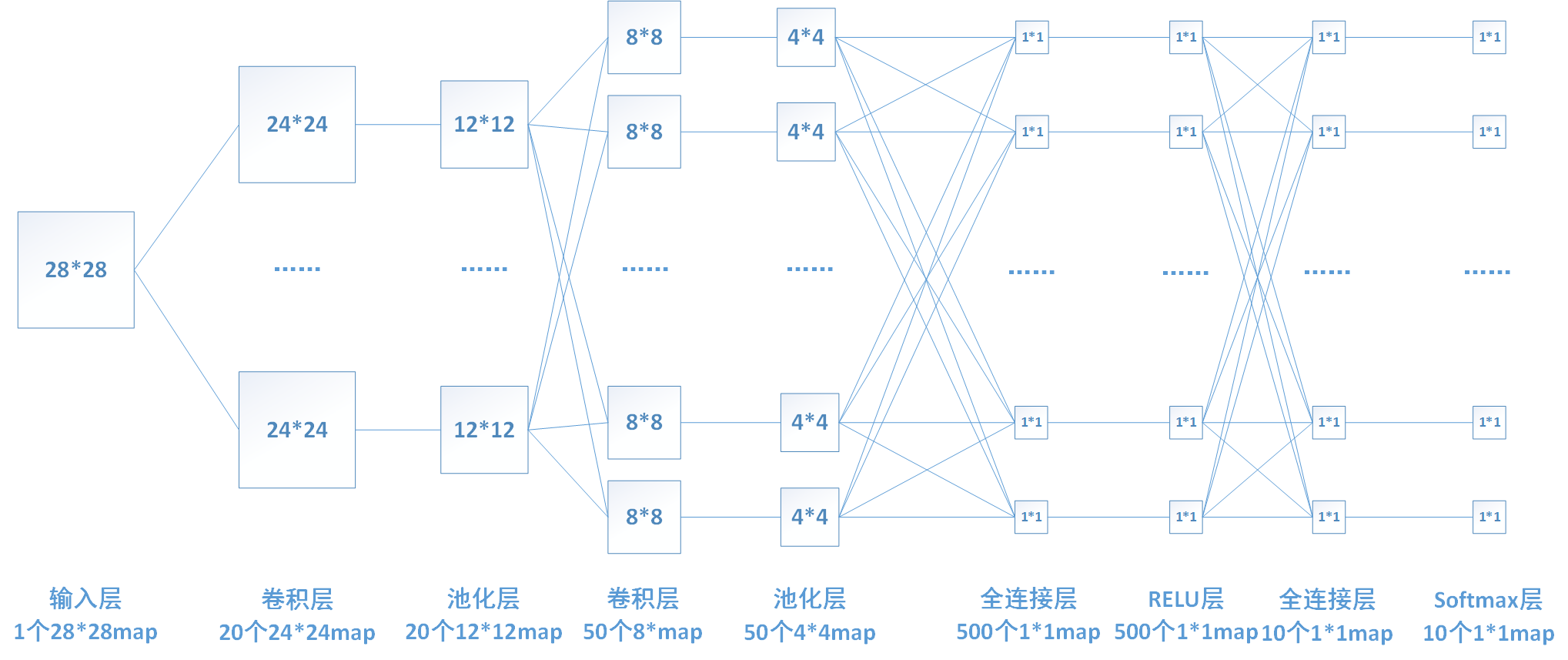
如图输入为 $28 \times 28$ 的图像,经过 $5 \times5$ 的卷积之后,得到一个 $(28-5+1)\times (28-5+1) = 24\times 24$ 的map。卷积层2的每个map是不同卷积核在前一层每个map上进行卷积,并将每个对应位置上的值相加然后再加上一个偏置项。
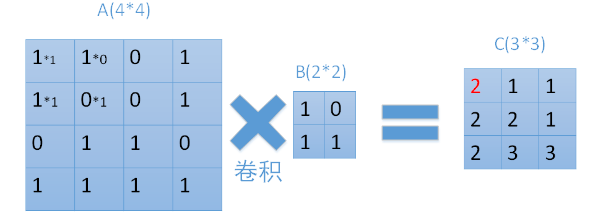
每次用卷积核与map中对应元素相乘,然后移动卷积核进行下一个神经元的计算。如图中矩阵C的第一行第一列的元素2,就是卷积核在输入map左上角时的计算结果。在图中也很容易看到,输入为一个 $4\times 4$ 的map,经过 $2\times 2$ 的卷积核卷积之后,结果为一个 $(4-2+1) \times (4-2+1) = 3\times 3$ 的map。
卷积前向的caffe实现
Caffe中卷积的实现十分巧妙,详细可以参考一下这篇论文: https://hal.archives-ouvertes.fr/file/index/docid/112631/filename/p1038112283956.pdf
下面是一张论文中的图片,看这张图片可以很清楚理解。从图中可以看出,卷积之前将输入的多个矩阵和多个卷积核先展开再组合成2个大的矩阵,用展开后的矩阵相乘。
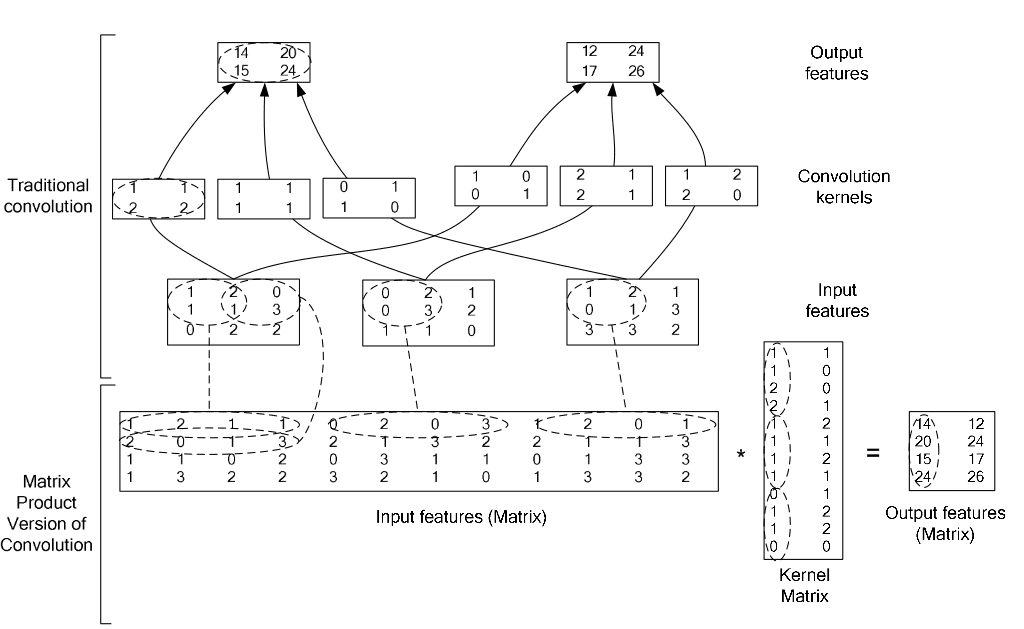
假设我们一次训练16张图片(即batch_size为16)。通过之前的推导,我们知道该层的输入为20个 $12\times 12$ 的特征图,所以bottom的维度 $16\times 20\times 12\times 12$ ,则该层的输出top的维度为 $16\times 50 \times 8\times 8$ 。
后向传播
反向梯度
在BP神经网络中,误差信号反向传递子过程比较复杂,它是基于 Widrow-Hoff 学习规则的。假设输出层的所有结果为,误差函数如下
$$E\left( w,b \right) =\frac{1}{2}\sum_{j=0}^{n-1}{\left( d_j-y_j \right) ^2}$$
而BP神经网络的主要目的是反复修正权值和阀值,使得误差函数值达到最小。Widrow-Hoff 学习规则是通过沿着相对误差平方和的最速下降方向,连续调整网络的权值和阀值,根据梯度下降法,权值矢量的修正正比于当前位置上 $E(w,b)$ 的梯度,对于第 $j$ 个输出节点有
$$\varDelta w\left( i,j \right) =-\eta \frac{\partial E\left( w,b \right)}{\partial w\left( i,j \right)}$$
假设我们选择激活函数:
$$f\left( x \right) =\frac{A}{1+e^{-\frac{x}{B}}}$$
对其进行求导:
$$
f’\left( x \right) =\frac{Ae^{-\frac{x}{B}}}{B\left( 1+e^{-\frac{x}{B}} \right) ^2}
$$
$$
=\frac{1}{AB}\cdot \frac{A}{1+e^{-\frac{x}{B}}}\cdot \left( A-\frac{A}{1+e^{-\frac{x}{B}}} \right)
$$
$$
=\frac{f\left( x \right) \left[ A-f\left( x \right) \right]}{AB}
$$
那么接下来针对 $w_{i,j}$
$$ \frac{\partial E\left( w,b \right)}{\partial w_{ij}}=\frac{1}{\partial w_{ij}}\cdot \frac{1}{2}\sum_{j=0}^{n-1}{\left( d_j-y_j \right) ^2} $$
$$
=\left( d_j-y_j \right) \cdot \frac{\partial d_j}{\partial w_{ij}}
$$
$$
=\left( d_j-y_j \right) \cdot f’\left( S_j \right) \frac{\partial S_j}{\partial w_{ij}}
$$
$$
=\left( d_j-y_j \right) \frac{f\left( S_j \right) \left[ A-f\left( S_j \right) \right]}{AB}
$$
$$
=\left( d_j-y_j \right) \frac{f\left( S_j \right) \left[ A-f\left( S_j \right) \right]}{AB}\cdot x_i
$$
$$=\delta_{ij}\cdot x_j$$
其中有
$$\delta_{ij}=\left( d_j-y_j \right) \frac{f\left( S_j \right) \left[ A-f\left( S_j \right) \right]}{AB} $$
同样,对于 $b_j$
$$
\frac{\partial E\left( w,b \right)}{\partial b_j}=\delta_{ij}
$$
这就是著名的 $\delta$ 学习规则,通过改变神经元之间的连接权值来减少系统实际输出和期望输出的误差,这个规则又叫做Widrow-Hoff学习规则或者纠错学习规则。
上面是对隐含层和输出层之间的权值和输出层的阀值计算调整量,而针对输入层和隐含层和隐含层的阀值调整量的计算更为复杂。假设是输入层第 $k$ 个节点和隐含层第 $i$ 个节点之间的权值,那么有
$$
\frac{\partial E\left( w,b \right)}{\partial w_{ki}}=\frac{1}{\partial w_{ki}}\cdot \frac{1}{2}\sum_{j=0}^{n-1}{\left( d_j-y_j \right) ^2}
$$
$$
=\sum_{j=0}^{n-1}{\left( d_j-y_j \right) \cdot f’\left( S_j \right) \cdot \frac{\partial S_j}{\partial w_{kj}}}
$$
$$
=\sum_{j=0}^{n-1}{\left( d_j-y_j \right) \cdot f’\left( S_j \right) \cdot \frac{\partial S_j}{\partial x_i}\cdot \frac{\partial x_i}{\partial S_i}\cdot \frac{\partial S_j}{\partial w_{kj}}}
$$
$$
=\sum_{j=0}^{n-1}{\delta_{ij}\cdot w_{ij}\cdot \frac{f\left( S_j \right) \left[ A-f\left( S_j \right) \right]}{AB}}\cdot x_k
$$
$$
=x_k\cdot \sum_{j=0}^{n-1}{\delta_{ij}\cdot w_{ij}\cdot \frac{f\left( S_j \right) \left[ A-f\left( S_j \right) \right]}{AB}}
$$
$$
=\delta_{ki}\cdot x_k
$$
其中有
$$
\delta_{ki}=\sum_{j=0}^{n-1}{\delta_{ij}\cdot w_{ij}\cdot \frac{f\left( S_j \right) \left[ A-f\left( S_j \right) \right]}{AB}}
$$
梯度下降更新
有了上述公式,根据梯度下降法,那么对于隐含层和输出层之间的权值和阀值调整如下
$$
w_{ij}=w_{ij}-\eta_1\frac{\partial E\left( w,b \right)}{\partial w_{ij}}=w_{ij}-\eta_1\delta_{ij}\cdot x_i
$$
$$
b_j=b_j-\eta_2\frac{\partial E\left( w,b \right)}{\partial b_j}=b_j-\eta_2\delta_{ij}
$$
而对于输入层和隐含层之间的权值和阀值调整同样有
$$w_{ki}=w_{ki}-\eta_1\frac{\partial E\left( w,b \right)}{\partial w_{ki}}=w_{ki}-\eta_1\delta_{ki}\cdot x_k$$
$$b_i=b_i-\eta_2\frac{\partial E\left( w,b \right)}{\partial b_i}=b_i-\eta_2\delta_{ki}$$
bp的缺陷
- 容易形成局部极小值而得不到全局最优值。BP神经网络中极小值比较多,所以很容易陷入局部极小值,这就要求对初始权值和阀值有要求,要使得初始权值和阀值随机性足够好,可以多次随机来实现。
- 训练次数多使得学习效率低,收敛速度慢。
- 隐含层的选取缺乏理论的指导。
- 训练时学习新样本有遗忘旧样本的趋势。
卷积的后向传播
在反向传播过程中,若第x层的a节点通过权值W对x+1层的b节点有贡献,则在反向传播过程中,梯度通过权值W从b节点传播回a节点。不管下面的公式推导,还是后面的卷积神经网络,在反向传播的过程中,都是遵循这样的一个规律。
卷积层的反向传播过程也是如此,我们只需要找出卷积层L中的每个单元和L+1层中的哪些单元相关联即可。我们还用此的图片举例子。
在上图中,我们的矩阵A11通过权重B11与C11关联。而A12与2个矩阵C中2个元素相关联,分别是通过权重B12和C11关联,和通过权重B11和C12相关联。矩阵A中其他元素也类似。
那么,我们有没有简单的方法来实现这样的关联呢。答案是有的。可以通过将卷积核旋转180度,再与扩充后的梯度矩阵进行卷积。扩充的过程如下:如果卷积核为 $k\times k$ ,待卷积矩阵为 $n\times n$ ,需要以$n\times n$ 原矩阵为中心扩展到 $(n+2(k-1))\times (n+2(k-1))$ 。具体过程如下:
假设D为反向传播到卷积层的梯度矩阵,则D应该与矩阵C的大小相等,在这里为3*3。我们首先需要将它扩充到 $(3+2\times(2-1))\times (3+2\times(2-1)) = 5\times 5$ 大小的矩阵,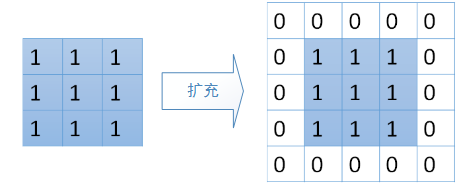
同时将卷积核B旋转180度:
将旋转后的卷积核与扩充后的梯度矩阵进行卷积: