
Rich feature hierarchies for accurate object detection and semantic segmentation是RBG大神的作品,提出了深度学习用于物体检测的开山之作r-cnn (Regions with Convolutional Neural Network Features)
IOU的定义
物体检测需要定位出物体的bounding box,就像下面的图片一样,我们不仅要定位出车辆的bounding box 我们还要识别出bounding box 里面的物体就是车辆。对于bounding box的定位精度,有一个很重要的概念,因为我们算法不可能百分百跟人工标注的数据完全匹配,因此就存在一个定位精度评价公式:IOU。
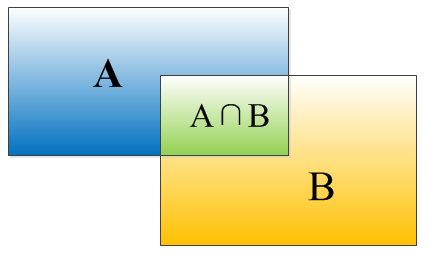
矩形框A、B的一个重合度IOU计算公式为:
$$IOU=\left( A\cap B \right) /\left( A\cup B \right) $$
就是矩形框A、B的重叠面积占A、B并集的面积比例:
非极大值抑制

就像上面的图片一样,定位一个车辆,最后算法就找出了一堆的方框,我们需要判别哪些矩形框是没用的。非极大值抑制:先假设有6个矩形框,根据分类器类别分类概率做排序,从小到大分别属于车辆的概率分别为A、B、C、D、E、F。
从最大概率矩形框F开始,分别判断A~E与F的重叠度IOU是否大于某个设定的阈值;
假设B、D与F的重叠度超过阈值,那么就扔掉B、D;并标记第一个矩形框F,是我们保留下来的。
从剩下的矩形框A、C、E中,选择概率最大的E,然后判断E与A、C的重叠度,重叠度大于一定的阈值,那么就扔掉;并标记E是我们保留下来的第二个矩形框。
就这样一直重复,找到所有被保留下来的矩形框。
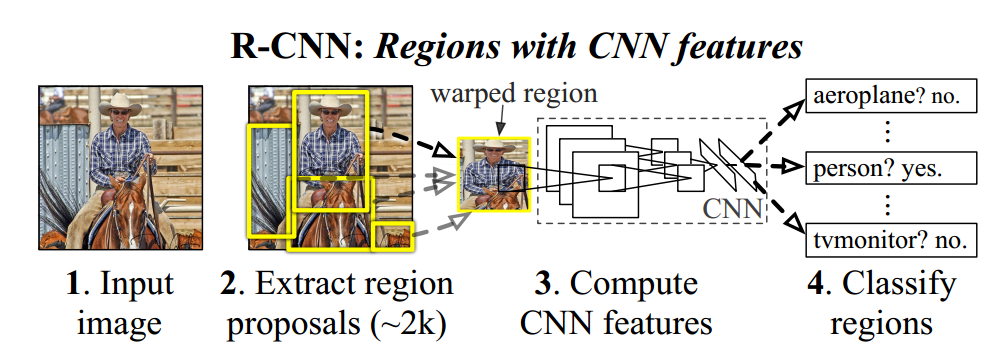
r-cnn的论文思想
在如今看来是非常简单的,
- 首先在原图中使用selective_search进行窗口的推荐推荐出2000个候选窗口。
然后采用CNN提取每个候选框中图片的特征向量,特征向量的维度为4096维。
接着采用svm算法对各个候选框中的物体进行分类识别
部分实现细节
selective_search
当我们输入一张图片时,我们要搜索出所有可能是物体的区域,这个采用的方法是传统文献的算法:《search for object recognition》,通过这个算法我们搜索出2000个候选框。然后从上面的总流程图中可以看到,搜出的候选框是矩形的,而且是大小各不相同。然而CNN对输入图片的大小是有固定的,如果把搜索到的矩形选框不做处理,就扔进CNN中,肯定不行。因此对于每个输入的候选框都需要缩放到固定的大小。下面我们讲解要怎么进行缩放处理,为了简单起见我们假设下一阶段CNN所需要的输入图片大小是个正方形图片227*227。因为我们经过selective search 得到的是矩形框,paper试验了两种不同的处理方法:

- 各向异性缩放,这种方法很简单,就是不管图片的长宽比例,管它是否扭曲,进行缩放就是了,全部缩放到CNN输入的大小227*227,如下图(D)所示;
- 先把bounding box图片裁剪出来,然后用固定的背景颜色填充成正方形图片(背景颜色也是采用bounding box的像素颜色均值),如下图(C)所示;
对于上面的异性、同性缩放,文献还有个padding处理,上面的示意图中第1、3行就是结合了padding=0,第2、4行结果图采用padding=16的结果。经过最后的试验,作者发现采用各向异性缩放、padding=16的精度最高.
fine-tuning阶段
我们接着采用selective search 搜索出来的候选框,然后处理到指定大小图片,继续对上面预训练的cnn模型进行fine-tuning训练。假设要检测的物体类别有N类,那么我们就需要把上面预训练阶段的CNN模型的最后一层给替换掉,替换成N+1个输出的神经元(加1,表示还有一个背景),然后这一层直接采用参数随机初始化的方法,其它网络层的参数不变;接着就可以开始继续SGD训练了。开始的时候,SGD学习率选择0.001,在每次训练的时候,我们batch size大小选择128,其中32个正样本、96个负样本(1:3)
note:作者在此论文中给出了卷积层和全连接层的一些特征,拿vgg16而言,网络的卷积层部分可以看作是sift等一样的特征提取器,但是对于全连接层是根据特定任务而言的,比如vgg16是用于图片分类,我们可以直接用其卷积层进行特征提取,而对于全连接,一般需要针对人脸任务进行一部分的微调。
一些附加的调参技巧:在cat vs dog 的二分类竞赛中,发现对于vgg16网络,如果仅仅改变全连接层,那么效果可以达到正确率95%,但是如果微调vgg16的conv5+全连接层可以达到正确率98%
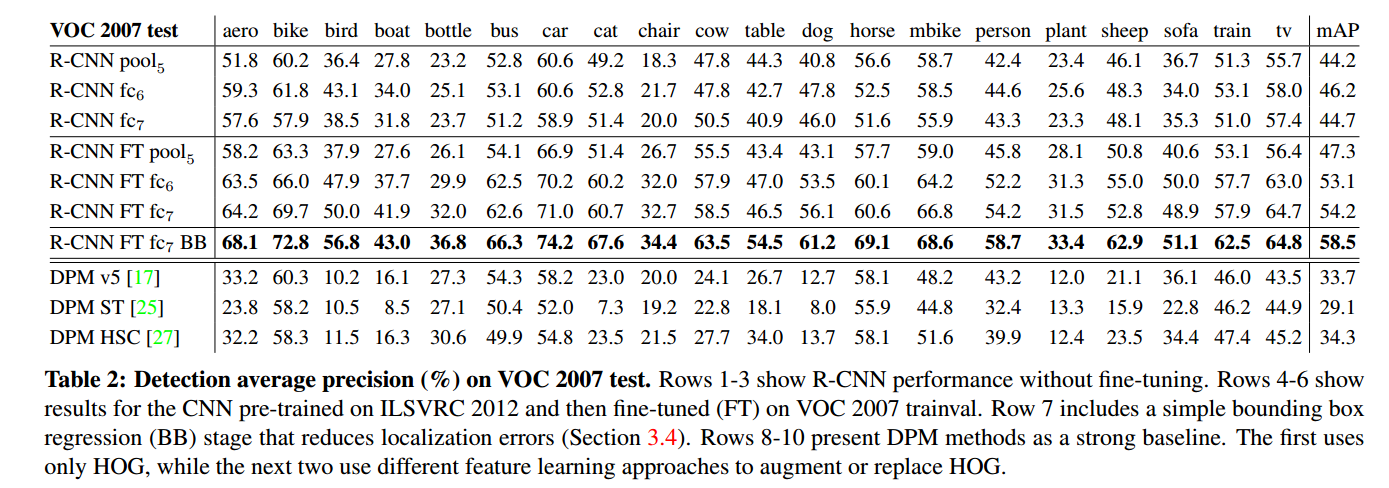
实验效果
具体的实验代码可以在
https://github.com/unsky/rcnn
中找到。