
卷积神经网络(CNN),训练数据的维度都是相同的,这样经过卷积池化后,得到的特征维度才能相同,进而才能将特征输入到分类器中训练分类器.输入维度相同这个限制太大了,这篇文章主要针对这个缺陷进行了改进,具体地就是加入了空间金字塔池化(Spatial Pyrimid Pooling),使得不同维度的输入最后都能得到相同维度的输出.所以每次在进行输入图片的时候都需要对原始的图片进行crop/warp操作,这样对一些过大过小的图片是不公平的。
spp-net的出发点
在对图片进行处理的时候,需要对图片进行crop/warp操作,
比如 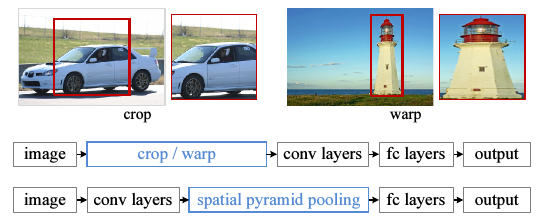
深究卷积神经网络为什么需要一个固定的输入,作者指出,在卷积层是可以任意尺寸的,但是全连接层需要一个固定大小的输入,所以限制整个网络需要固定输入的是全连接。
spp-net的结构
SPP是词袋模型(Bag-of-Words)的扩展.词袋模型没有特征的空间信息(就像它只能统计一个句子中每个单词的词频,而不能记录词的位置信息一样).在深层CNN里加入SPP会有3个优势: 1) 相比之前的滑动窗池化(sliding window pooling),SPP可以对不同维度输入得到固定长度输出. 2) SPP使用了多维的spatial bins(我的理解就是多个不同大小的窗),而滑动窗池化只用了一个窗. 3) 因为输入图片尺度可以是任意的,SPP就提取出了不同尺度的特征.作者说这3点可以提高深度网络的识别准确率.
所以作者提出了如下的结构:

详细设计
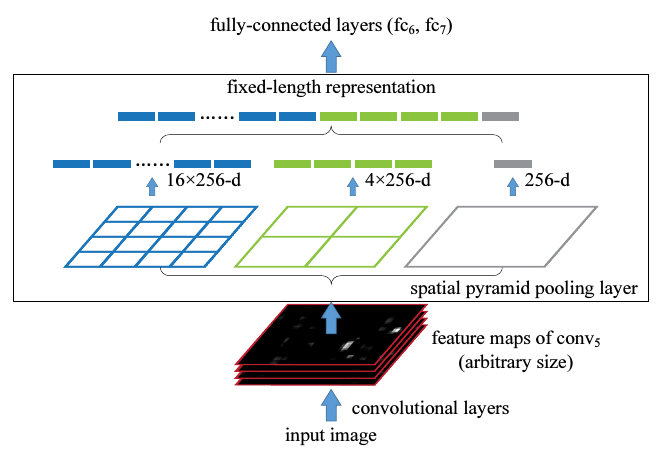
若输入维度不同,卷积层会输出的不同大小的feature map.其实把BoW用在这些feature map上已经可以解决固定输出的问题了,但SPP使用local spatial bins来做池化,保留了空间信息,是一个提升.SPP的原理其实就一句话,SPP的spatial bins(也就是池化时候的窗口大小)是和输入图片的大小成比例的,所以spatial bins的数目也就固定下了,和输入大小无关.原理是下图.无论feature map的大小是多少,总是可以把一个feature map分成4x4,或者2x2,或者1x1,只是每一个小方块大小不一样.
具体地,在一个CNN里,把最以后一次池化层去掉,换成一个SPP去做最大池化操作(max pooling).如果最后一次卷积得到了k个feature map,也就是有k个filter,SPP有M个bin,那经过SPP得到的是一个kM维的向量.我的理解是,比如上图中第一个feature map有16个bin,一共有256个feature map,每一个经过16个bin的max pooling得到16个数,那256个feature map就是16x256的向量了.SPP的bin大小可以选择多个,所以经过SPP还能产生4x256,1x256维的向量.
我们可以对不同比例,不同大小的图片进行处理,而且使用同一个CNN,只是对不同大小的图片,在最后的SPP里,bin的大小不同,但最后得到的特征确实相同维度.这样,我们把一张图片resize成不同尺度,放到同一个CNN里训练,就能得到不同尺度下的特征,就和SIFT类似了.
训练
虽然SPP理论上可以直接用BP来训练参数,但现有的使用了GPU的CNN工具,比如caffe和cuda-caffe都只能以固定大小的图片作为输入.作者使用了caffe,但是用了一些技巧来实现SPP的训练.
单一大小训练
如果一个图片大小固定,比如224x224,那么我们就能计算出它的池化窗口(bin)的大小.比如经过第五个卷积层conv5之后得到的feature map是a x a(13x13),如果金字塔大小n x n,那么窗口大小就是ceil(a / n), 步长是floor(a / n).我们可以用ll个不同大小的窗口,比如3x3, 2x2, 1x1.然后把这ll个输出连接起来,送入之后的全连层.下图是这样3个窗口和最后的全连层的的配置文件.

多个大小训练
我们再考虑一种输入大小(180x180),这个180x180的直接取224x224图片的按尺度缩放图片,这两张图除了解析度不同别的都相同.180x180的图片经过第五层卷积后的feature map是10x10,这时我们依然用刚才的公式,窗口大小就是ceil(a / n), 步长是floor(a / n),这样的话后得到的特征长度与之前的224x224的特征长度相同.举个例子,如果金字塔是3*3,即n=3,那么对于第一种大小,窗口长为5,步长4,第二中大小,窗口4,步长3,如下图.
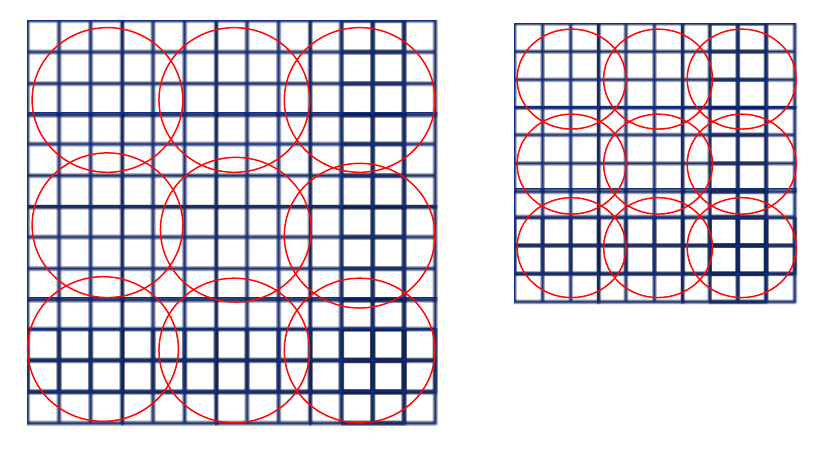
红色区域代表窗口,经过最大池化后,两张图得到的特征向量长度均为3x3=9.所以180的网络和224的网络参数完全一样,于是SPP训练阶段,对于这两种网络只要共享参数即可.
但是在实际训练时,为了减少不停转换网络带来的开销,需要使用全部数据一次训练一个网络,然后再换成第二个,作为一次迭代.所以作者根本没有实现训练不同大小输入的CNN的BP算法,只是针对各种各样大小不同的输入,定义出不同的网络,但这些网络实际上参数都相同,于是就可以用现有工具来训练.
SPP-NET物体检测实验
R-CNN进行物体检测的方法是,首先从每张图片选出2000个候选窗口,然后把窗口变形到227x227,把每个窗口送入网络计算特征,然后训练SVM进行二分类.R-CNN效果很好,但是对每一张图片的2000个窗口都要送进卷积网络计算,很费时间.
SPP-NET可以直接对一张整图计算feature map(以及不同尺度的这张图片),然后只需要在feature map的不同区域进行SPPooling即可,没有了像R-CNN的从头卷积那一步,如下图.
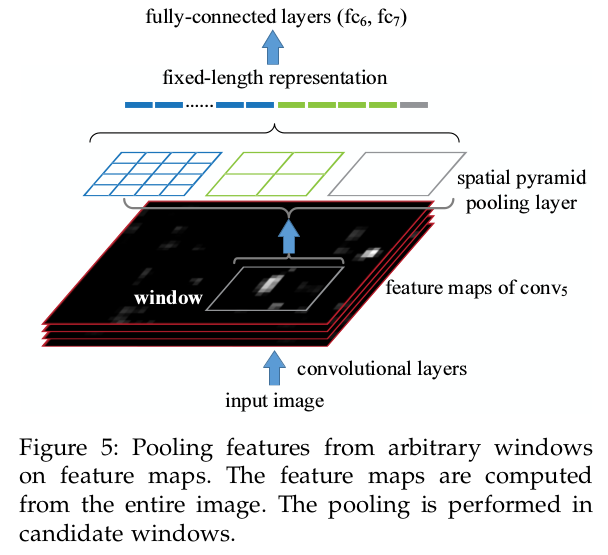
具体的源码可以在 https://github.com/unsky/SPP_net 中找到。