
HyperNet: Towards Accurate Region Proposal Generation
and Joint Object Detection
本篇论文发表于2016 IEEE Conference on Computer Vision and Pattern Recognition
论文下载地址:
http://ieeexplore.ieee.org/document/7780467/
HyperNet: Towards Accurate Region Proposal Generation
and Joint Object Detection
本篇论文发表于2016 IEEE Conference on Computer Vision and Pattern Recognition
论文下载地址:
http://ieeexplore.ieee.org/document/7780467/
简介一下物体检测目前最火的框架:
在这两年的物体监测论文发展中,faster r-cnn 属于一篇分水岭是的文章,在此之前,大多延续的框架是region proposal + classification.其主要还是在做分类问题,faster-rcnn框架,第一次提出了 region proposal network,这个区域推荐网络是直接对feature maps做回归,详细点就是对每个sliding window 做k(k is 9 in faster r-cnn) 个anchor的回归.接着这个思想you only look once, ssd直接用回归来做检测问题盛行起来。
总结如下:
经典框架:region proposal +classification
最新框架:regression
论文出发点:
这是一篇2016年的论文,基本是在fast r-cnn的阶段进行研究,对于fast r-cnn有很大的缺点,因为在深度网络的高层使用区域推荐,来产生大量的区域推荐从而进行下一阶段的分类。但是直接在高层做区域提取往往会对小的物体不敏感,意思就是卷没了。在高层可能只剩下很大的物体,所以这些制约了最终的分类性能能。论文原话:
Although the latest Region Proposal Network method gets promising detection
accuracy with several hundred proposals, it still struggles in small-size object detection and precise localization (e.g.,large IoU thresholds), mainly due to the coarseness of its
feature maps.
意思就是就算使用了阈值来进行筛选,区域推荐依然需要推荐出大约2k个窗口来进行强分类。而大量的负样本掺杂在其中,同时小的物体还没有推荐出来。
问题:
- 推荐出的窗口太多,限制了速度。同时引入了更多的hard negatives增加了分类的难度。
- 因为在高层做卷积,遗失了很多小物体区域。
其实这俩问题属于很经典的问题,作者并没有提出很native的问题,大家基本都围绕这个问题在做工作,看他们怎么做的吧
网络框架:
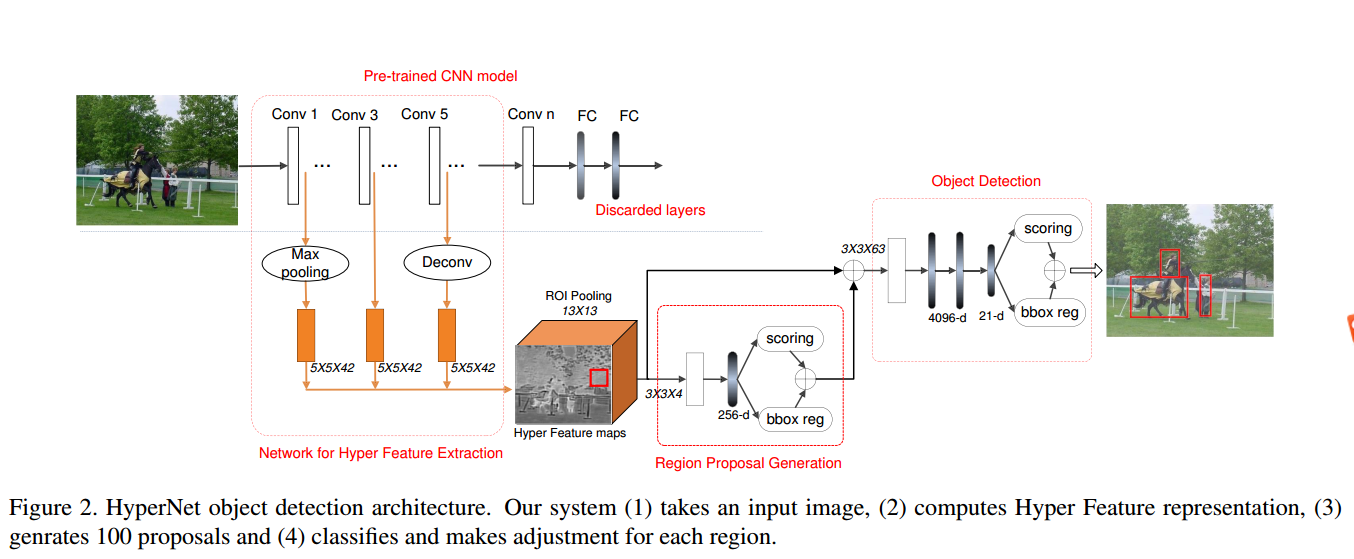
整体网络结构分成三部分:
- Pre-train cnn modal 他使用了vgg16/19的 conv1,conv3和conv5,更高层的conv n 和 fc都被舍弃了。
- Network for hyper feature extraction 层级特征提取,这部分主要负责在各层提取特征,然后进行concat(这个idea的思想在ssd也能找到,属于比较好像的idea,提取不出小物体,就在底层提取嘛,,这在 is faster r-cnn is doing well for pedestrian detection 中思想已初见)。
- Region proposal generation 部分是论文的核心,在这里使用层级特征来进行区域推荐。
- Object detection就是个强分类器阶段。
以上1-3步骤对应于经典框架的region proposal部分,4步骤对应于classification阶段。
下来挨个看每一部分。Pre-train cnn modal
没啥好说的,pre-train cnn modal as a feature extractor basing on Transfer learning..Network for hyper feature extraction
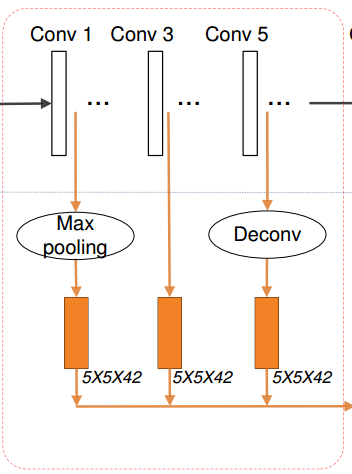
目标是为了从各层提出特征进行concat,但是问题来了,拿VGG16来说,底层和高层之间的feature maps size 是很不一样的。怎么进行concat?
作者解决方法:对每一层使用不同的策略进行特征提取 - 对底层,使用max –pool进行下采样
- 对中层,啥都不干
- 对高层使用deconv进行上采样
讲真,这种策略看起来十分工程化,很不优美。。。
进行完以上的操作需要使用一个卷积操作(上图褐色部分)对他们卷积到同一维度:作者的原话:
The Conv operation not only extracts more semantic features but also compresses them into a uniform space.
意思是,这个卷积操作不止提取了更深的语意信息,而且将multi-level feature 映射到uniform space了。(自我猜想:虽然道理是这么个道理,但是都已经上采样和下采样到中间level为什么不直接使用一个卷积或者直接不用卷积来进行concat 这样三个卷积训练起来会不会很low..)
最终的最终我们需要使用local response normalization (LRN)对concat之后的特征进行正则化,(更加怀疑那三个卷积的怎么更新。。。)
这么做作者说有三个好处:
- Multiple levels’ abstraction. Inspired by neuroscience, reasoning across
multiple levels has been proven beneficial in some computer
vision problems。神经学说借助多层特征的推理已经被很好的运用于视觉。(明明是玄学) - Appropriate resolution分辨率变合适了,这么concat下来1000600的图片变为250150。
- Computation efficiency. All features can be precomputed before region proposal generation and detection module. There is no redundant computation.
这点我个人是非常赞同的,深究一下,从我们最开始的出发点可以看出。
如果我们在高层来进行区域推荐,会忽略小目标。
如果我们在底层进行区域推荐,对于大目标,它本应该进行更深的语义卷积,但这种策略没有做,结果就是丢失了更深层的特征。
说白了就是,在高层对小目标不好,在底层对大物体不公平。Region Proposal Generation
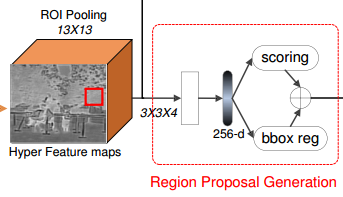
这一层和rpn回归网络很像,不同的是,其由ROI pooling layer(1313), a Conv layer(33*4) and a Fully Connect (FC) layer(256-d),不同的是其多了一个卷积层。后面的操作都和rpn一样,需要使用阈值来进行极大值抑制(0.7)选1K个窗口,然后选top200进行下一步的操作,也就是最终推荐出200个窗口。
思考:此网络和rpn网络相似度极高,为什么,它可以很猛的选择top200而rpn不敢?
Rpn生成的网络推荐的2000个窗口中,可以保证很大的recall,因为有很多正样本和hard nagitives混杂在一起,而此网络可以选择top200而用于很高的recall猜测一方面其得益于concat的特征,或者多了的卷积层(stranger than rpn in classification…)?
Object Detection
分类器,一个中规中矩的分类,损失函数还是用r-cnn的
训练策略

论文提出了一个6步训练策略,在训练的fineturning阶段可以做到object classification网络和region generation network联合反向更新。
加速策略:
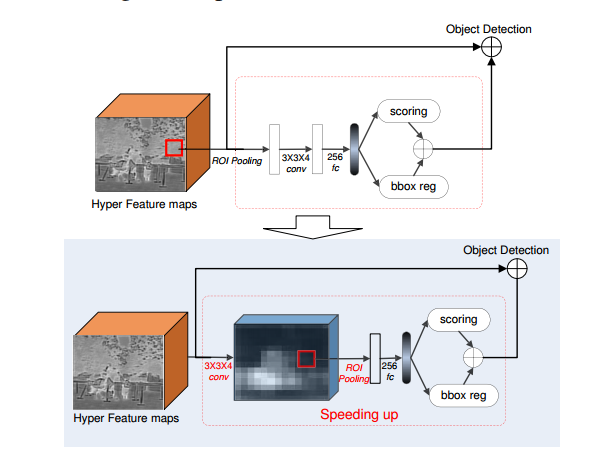
这么做还是太慢了,作者说,主要话费时间的地方是区域生成网络,而区域网络最费时间的地方是对大推向做iou pooling(占了70%的时间)所以坚决策略,先卷积再iou-pooling…
实验:
作为主打区域推荐,当然要计算下recall
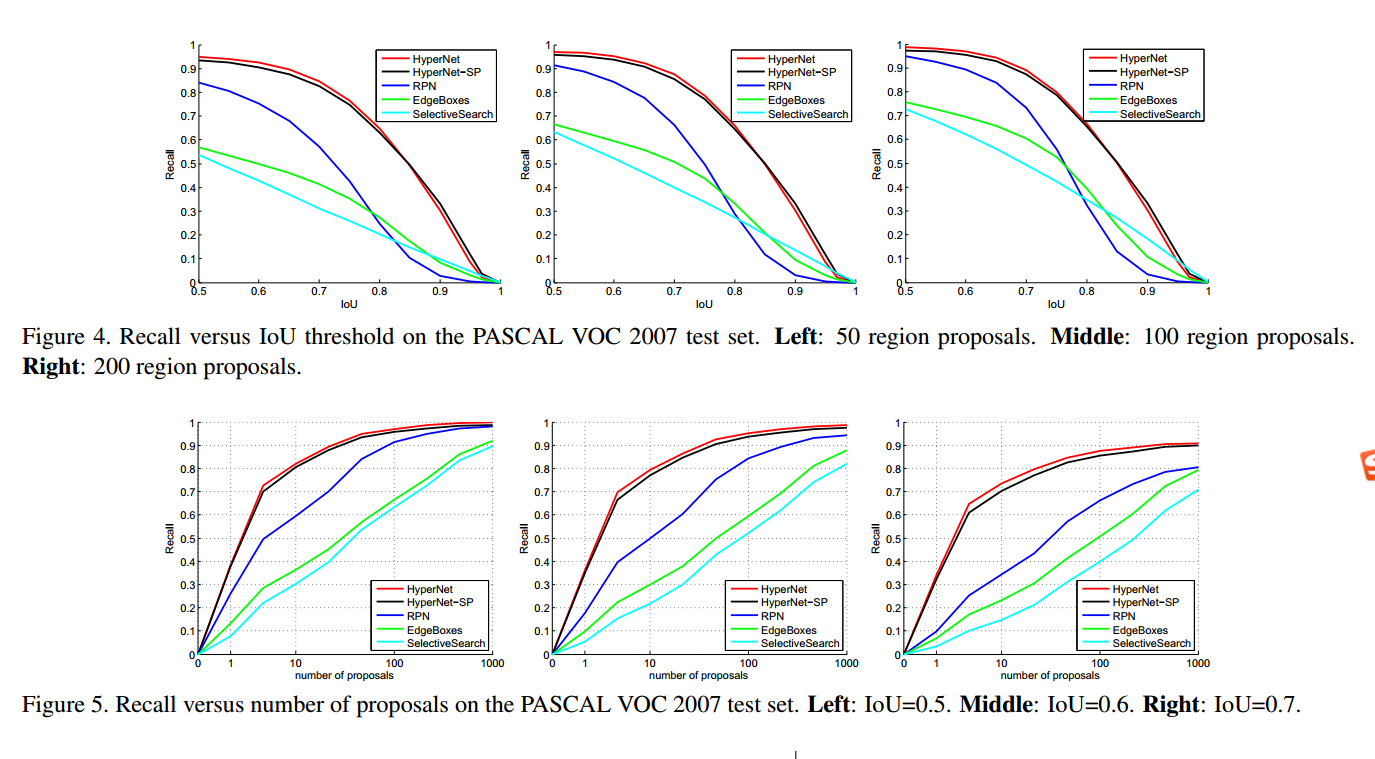
可以看到其在200proposal的时候,recall真的提了一大截。很赞。
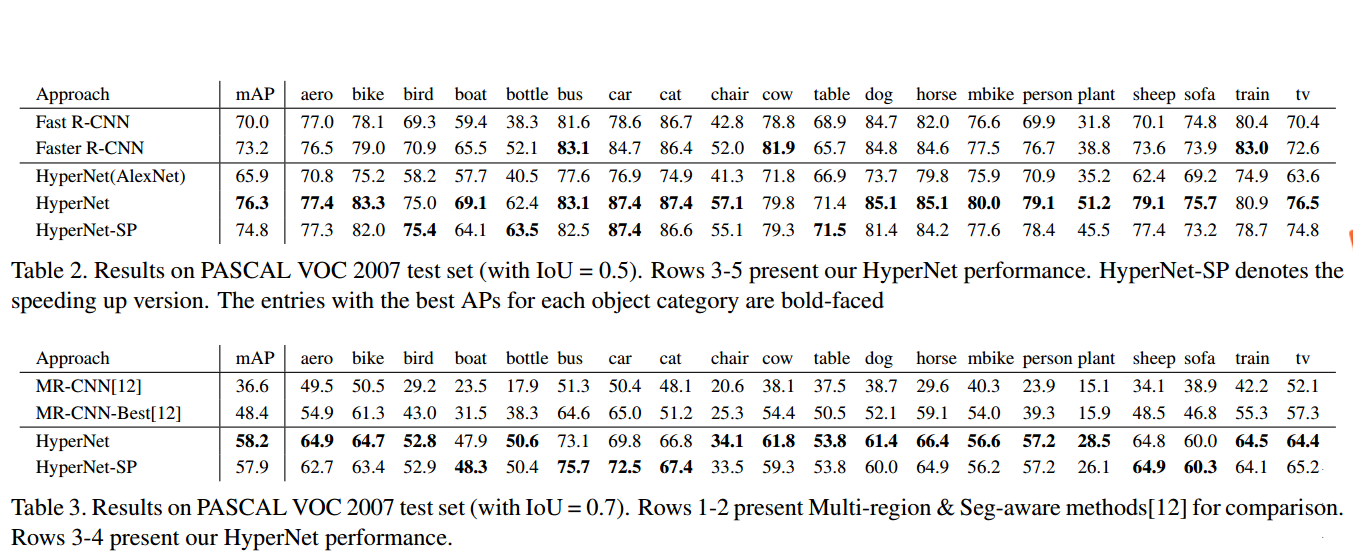
正确率
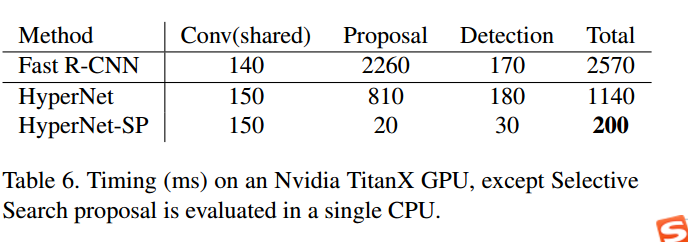
速度
论文就结束了.
思考:
对于层级特征目前运用的比较多,作者也将层级特征进行了可视化,从可视化的结果上可以看出对于小物体它有近似放大的效果,这很可能得益于对下层特征进行下采样的结果。
这个模型明显有改进的方法,就是将object detection网络和区域生成网路合并,就成了ssd。。。。哈哈哈天下人的idea都一样。
整体评价:如果不是文章赶得快,这论文在ssd和yolo之后就没有价值了。